Facility management operations don't break because you hired the wrong people or bought the wrong software. They break because you outgrew your execution model, and nobody tells you that's what happened.
If you're managing 100-1,000+ engineers across multi-site, multi-trade estates with compliance obligations, you've probably already tried the standard fixes:
- More planners to coordinate the chaos
- A better CAFM system to track everything
- Stricter processes to reduce variability
Each has probably helped you, briefly. Then it stopped working.
In this guide, we explain why those tactics hit diminishing returns at scale.
You'll also learn:
- Why complexity compounds non-linearly as you grow
- Where the execution gap actually emerges
- How to evaluate technology as infrastructure rather than features
- And more
So if you're looking to find out how to manage multi-trade, multi-site operations with real compliance exposure, this guide is for you.
Key Takeaways
- Facility management doesn't fail because of bad hires or wrong software. It fails because operations outgrow their execution model, and the breakdown looks like people problems when it's actually architectural.
- Scaling facilities management is not linear. Doubling your engineer count from 50 to 100 doesn't double coordination work, it quadruples it or worse. Every new trade adds sequencing dependencies with every other trade. Every new site creates geographic blind spots and compliance windows that overlap in ways planners can't see.
- The execution gap emerges between 100-300 engineers. Planning processes that worked brilliantly at 50 engineers stop scaling because human coordination hits hard limits. A reactive callout cascades across PPM schedules, delays statutory compliance, forces backtracking, and triggers unbudgeted overtime that shows up as operational inefficiency.
- CAFM systems track failure perfectly but can't prevent it. Your CAFM recorded every step of that cascading failure, but tracking isn't executing under live change. Most FM platforms were built as systems of record, not live execution engines that can handle constant disruptions across multi-trade, multi-site operations.
- Hiring more planners often makes things worse. The planner productivity paradox shows an inverse relationship between planner headcount and engineer productivity. More planners create more coordination overhead, not less.
- This guide reframes FM scaling as an execution architecture problem. Your operations crossed a threshold where the best practices that got you here now work against you because they weren't built for this level of complexity.

Why Facility Management Gets Harder as You Grow
When facility management operations scale from 50 engineers to 500, most leaders assume they're dealing with a multiplication problem.
Twice the headcount means twice the work, right?
You hire more planners, buy better software, tighten your processes, and expect things to smooth out.
They don't. They get exponentially worse.
That's because FM scaling is combinatorial. Here's what we mean:
Doubling your engineer count doesn't double your coordination load. It quadruples it, sometimes worse:
- Every new trade you add brings more jobs, but also sequencing dependencies with every other trade.
- Every new site adds capacity, but it also creates geographic blind spots, compliance windows that overlap, and emergency work that cascades across regions.
Growing your FM operations equals chaos that you're managing better than most people could. But that still feels like you're losing.
Here's what "harder" actually means at scale:
You don't have more work, the work becomes fundamentally different.
A reactive callout doesn't just disrupt one engineer's day, now it:
→ Disrupts the PPM schedule for a site.
→ Which delays a compliance visit,
→ Which forces another engineer to backtrack across town
→ Which triggers overtime you didn't budget for
→ Which shows up in next quarter's margin analysis as "operational inefficiency."
Worst of all:
Your CAFM system tracked every step of that failure. But it couldn't prevent any of it.
That's because tracking isn't the same as executing under live operational changes.
The planning rhythms, the coordination meetings, the veteran planner who "just knew" how to sequence jobs don't scale linearly. Human coordination can't.
At some point (usually between 100-150 engineers), you cross into an operational regime where your best practices actively make things worse, because they were designed for a simpler problem.
This guide is for leaders managing that crossing point, or who've already crossed it and can't figure out why everything that used to work has stopped working.
What Kind of FM Leader This Guide Is for
You're in the right place if you're running:
- 100-1,000+ field engineers across multiple trades
- Multi-site or multi-region estates, not single-building operations
- A mix of planned preventative maintenance and reactive or emergency work
- Operations with statutory compliance obligations, contractual SLAs, or penalty exposure
- A team where planner headcount keeps growing but engineer productivity keeps dropping
This guide isn't for you if you're managing:
- Single-building or low-complexity estates where PPM is predictable and reactive work is rare
- Static, PPM-only schedules without meaningful compliance pressure
- Operations where a good spreadsheet and a sharp planner can still see the whole picture
If that second list describes you, you're not facing a scaling problem yet. You will eventually, but the frameworks in this guide will feel like overkill. We'd rather be honest about that now than waste your time.
For everyone still reading:
The diagnosis we're about to walk through reframes FM scaling failures as execution architecture problems, not people problems, or process problems.
You outgrew an execution model that was never designed to handle combinatorial complexity.
And nobody told you that's what happened.
What Scale Actually Means in Facilities Management
Scale in facilities management is measured in coordination complexity. A 500-engineer operation managing multi-trade work across a national estate is fundamentally different from a 50-engineer operation in its coordination problem.
But that's not most people think of when they evaluate scale.
When most people evaluate facility management operations, they measure scale by counting things:
- Number of engineers
- Number of sites
- Number of assets under management
That's not wrong. But it misses what actually makes large FM operations hard to run.
Here's what actually makes scaling facility management operations difficult to do:
Estate Size
The number of sites you manage matters less than how those sites interact with your operational model. Managing 200 buildings sounds straightforward until you consider what that means for planning visibility.
With a small estate, your planners can keep mental models of each site.
For example:
- They know which buildings have temperamental boiler systems
- They know which site managers prefer morning visits
- They know which locations have difficult parking
That informal knowledge compensates for gaps in your CAFM system.
Beyond 50 sites, that breaks.
No planner can hold the operational nuances of 100+ buildings in their head. You lose the informal coordination layer that made smaller operations work.
Suddenly, you're dependent on your systems capturing every detail. Most don't.
Estate size also determines whether you can collocate engineers near their work.
A dense urban portfolio might allow engineers to cover 8-10 sites efficiently. A regional estate with sites spread across 200 miles means every job includes significant travel time.
That collapses your capacity and makes emergency response unpredictable.
Trade Diversity
Single-trade operations scale relatively cleanly. If you only do electrical work, your scheduling problem is essentially:
Match available electricians to sites that need electrical work
→ Optimize for geography
→ Optimize for urgency
Multi-trade FM operations face combinatorial complexity.
An HVAC job might require:
→ An electrician first to isolate power
→ An HVAC engineer to replace the unit
← The electrician again to reconnect and test
→ A building fabric issue might need a plumber
→ Then a plasterer
→ Then a decorator
And so on.
All of this has to happen in sequence. (Not parallel.)
This creates sequencing dependencies that make your planning problem exponentially harder.
You're still matching field technicians and engineers to jobs, but you're also orchestrating multi-step workflows.
For example:
Trade A must finish before trade B can start, and if trade A runs late or gets pulled to an emergency, the entire chain collapses.
The skill-matching problem compounds this, because you're teams and field engineers aren't interchangeable. Every job requires an engineer with this specific combination of skills, certifications, and geographic availability.
For example, some engineers are qualified for high-voltage work, others aren't. Some hold water hygiene certifications, others don't.
At 100+ engineers across six trades, this matching problem becomes brutal.
Compliance Density
High compliance density means your operation runs close to a single missed job triggering escalation, audit burden, and penalty exposure. It measures how tightly packed these obligations are, and how little slack you have to absorb disruption.
Statutory compliance obligations create hard deadlines that reactive work constantly disrupts:
- Your annual fire alarm testing must happen within a specific compliance window.
- Your gas safety inspections have legally mandated intervals.
- Your electrical testing, water hygiene sampling, and emergency lighting checks all have non-negotiable schedules.
Small operations handle this through calendar discipline and manual tracking.
Large operations face compliance cascades, where missing one deadline creates a ripple effect across other scheduled work.
The problem intensifies with contractual SLAs that carry penalty clauses.
You might have 200 sites with different compliance calendars, different SLA response times, and different penalty exposures.
A high-priority reactive callout at a site with a 4-hour SLA pulls an engineer away from a compliance job with a narrow window, which then requires rescheduling. This affects another engineer's route, which delays a different compliance obligation.
Geographic Spread
A regional FM operation (sites within 50 miles of a central hub) faces fundamentally different execution challenges than a national operation spanning 500+ miles across multiple regions.
Geographic spread impacts planner oversight:
- Can your planners physically visit sites when something goes wrong?
- Are they coordinating remotely based on incomplete information?
- Can your field supervisors actually supervise?
- Are they managing teams they rarely see in person?
Parts logistics becomes a distinct operational challenge at scale.
A regional operation might maintain a central parts depot with same-day courier delivery.
A national operation needs distributed parts inventory. This creates stock management complexity, duplicate inventory costs, and situations where the right part exists in your system but not in the region where you need it.
Time zones matter for true national or international estates.
Planning a UK-wide operation is hard. Planning work across UK, EU, and US time zones means your coordination problem never sleeps.
There's always live work happening somewhere. There's always potential for emergencies to disrupt carefully built schedules.
Reactive Work Volume
Planned preventative maintenance (PPM) is manageable. You know what needs to happen, when, and with which skills.
Reactive work creates a constant replanning burden. This includes emergency callouts, tenant requests, equipment failures.
We've found that operations with reactive work above 30% of total volume hit a tipping point where planning becomes replanning:
→ You build tomorrow's schedule, then overnight callouts reshuffle half of it.
→ You rebuild the schedule at 8am, then a morning emergency pulls two engineers off their routes.
→ By midday, you're rebuilding it again.
This is the nature of FM operations at scale.
With 500+ assets across a large estate, equipment failures follow statistical distributions:
You will have X emergencies per week → They will disrupt optimized schedules.
High reactive volume trains your entire operation to expect chaos, which undermines attempts to impose structure.
- Engineers stop trusting their schedules because they know they'll change.
- Planners stop optimizing routes because they know they'll get disrupted.
Your operation has to adapt to constant disruption, rather than fight it.
That's what scale actually means in facilities management.
Not bigger numbers. Different physics.
Why Hiring More Planners Stops Working for FM at Scale
Hiring more planners for facility management operations doesn't work because planner headcount can grow faster than the number of field engineers, while your margins compress and your compliance risk increases.
When your facility management operations start showing cracks (missed compliance windows, engineers waiting for instructions, reactive work trampling your PPM schedule) the instinctive fix is to hire planners.
More coordination capacity should mean better control, right?
It works at first:
One experienced planner can coordinate 20-30 engineers effectively when the work is mostly planned preventative maintenance across a geographically concentrated patch.
They know the engineers, they know the sites, they can juggle the occasional emergency without losing the thread on compliance schedules.
Then you scale past 100 engineers. Maybe 150. The planner-to-engineer ratio starts degrading. You're now at 1:15, then 1:12, then 1:10. The math seems simple:
Hire more planners to get back to that efficient 1:25 ratio.
But you don't get efficiency back. You get something worse.
We've watched this pattern repeat across dozens of large FM operations, and the failure mode is always the same.
More planners don't create more coordination capacity. Hiring more planners creates coordination overhead that consumes the capacity.
What Hiring More Planners Looks Like in Facility Management Operations
Every new planner you add creates more handoffs, more communication overhead, and more territorial boundaries that slow down execution.
An engineer who used to call one planner for everything now has to figure out which planner owns which piece of work. Planner A handles the northern region. Planner B owns the PPM schedule. Planner C coordinates reactive calls. Planner D manages multi-trade jobs.
What happens when reality doesn't respect these boundaries?
Let's say an engineer gets assigned a PPM job by Planner A. He arrives on site and discovers an access issue. For example, the keyholding contact changed, and nobody updated the system.
The engineer calls Planner B, who actually owns that site relationship. Planner B needs to coordinate with the client's facilities contact.
Meanwhile, Planner A has already sequenced three other jobs behind this one, so now Planner A and Planner B need to coordinate the knock-on effects of the delay. The engineer waits 45 minutes for clarity on whether to proceed, skip and return, or move to the next job.
That 45-minute delay isn't an edge case. It's Tuesday.
The engineers aren't less capable.
The planners aren't doing anything wrong.
But engineer utilization drops because they're spending more time reporting status, waiting for instructions, and navigating the org chart of who controls what decision.
Why Coordination Overhead Prevents You from Scaling Your FM Operations
Coordination overhead grows faster than planner capacity because the complexity is combinatorial:
- Two planners need one communication channel.
- Three planners need three channels.
- Four planners need six.
By the time you have eight planners trying to coordinate a multi-region, multi-trade operation, you've created 28 potential communication paths, and every decision has to navigate that mesh.
Meanwhile, the planners themselves stop doing what you hired them to do:
Strategic coordination and capacity planning.
Instead, they become the execution layer by default:
- They're manually re-sequencing routes throughout the day because an emergency call disrupted the morning plan.
- They're calling engineers mid-job to redirect them because a site just called with an urgent issue.
- They're constantly replanning around live disruption instead of building resilient plans that can absorb normal variation.
At 300+ engineers, we've seen FM operations with 25-30 planners on the team. That's a 1:10 ratio, and somehow the operation feels more chaotic than it did at 100 engineers with five planners.
The planners spend half their time coordinating with each other. Field service engineers spend 15-20% of their day waiting for instructions or clarification.
Reactive work still tramples the PPM schedule because no single planner has enough visibility to reoptimize the entire day's work across all regions and trades.
And here's what makes this particularly painful:
You can't solve it by hiring better planners or giving them better processes.
This is a structural ceiling on human coordination capacity.
What Is the Structural Ceiling for Facility Management Operations
A human planner can track about 15-25 jobs simultaneously in their working memory (a live context of where each engineer is, what they're doing, what's queued next, what could go wrong). Beyond that, they're managing by spreadsheet and prayer.
When you have 200 engineers doing 1,200 jobs across a week, that's not a coordination problem that scales with human cognitive capacity. No amount of heroic effort, overtime, or motivational speeches changes the math.
You hit the ceiling.
Planners become reactive dispatchers instead of proactive coordinators. Engineers become less productive despite working harder. Your cost-to-serve increases even as your revenue scales.
The facilities management planning team that was supposed to create leverage and control has instead become a bottleneck.
That planner bottleneck slows down execution and burns out good people who are doing exactly what they should be doing within a system that can't scale this way.
This is the point where most FM operations leaders realize they need a fundamentally different execution model.
Not more planners.
Not better software to help planners track more jobs.
What you need is an actual execution layer that removes humans from the real-time sequencing and coordination loop.
Why CAFM Tools Don't Scale Facility Management Execution
Computer-Aided Facilities Management (CAFM) and Field Service Management (FSM) software were never designed to handle live execution under constant change.
CAFM and FSM platforms are excellent at maintaining comprehensive asset registers, track preventative maintenance schedules, store compliance documentation, generate work orders, and report on SLA performance with precision.
This is what these tools were built for. And for facility management operations that need an auditable system of record, they're essential infrastructure.
CAFM platforms assume work happens as scheduled.
They optimize routes and assignments based on the information available when the schedule is built. That optimization happens once, produces a plan, and then hands it off to planners and engineers to execute.
In a static world where every job runs on time, no reactive work comes in, and every engineer shows up exactly where expected, that approach works perfectly.
However:
That world doesn't exist in facility management operations at scale.
The Execution Gap of CAFM Software
Your CAFM platform has all the data, but the problem is that it can't make the execution decisions that need to happen in the next five minutes.
Here's what actually happens when you use CAFM tools:
→ Your CAFM platform builds the perfect plan on Sunday night for Monday's work:
- Engineers are assigned to jobs based on skills, location, compliance windows, and SLA priorities.
- Routes are optimized.
- The schedule looks clean.
→ By 9am Monday morning, three engineers are stuck in traffic on the M25, two emergency callouts have come in from critical sites, and one planned access window has been cancelled because the building manager is out sick. The plan you optimized 12 hours ago is now obsolete.
But your CAFM platform can't re-optimize in real time:
- It created the plan
- It stored the assignments
- It's waiting for engineers to log job completions
It's tracking what's happening. But it's not adapting to what's happening.
So what fills that gap?
Your planners.
They're on the phone, reassigning jobs manually, checking spreadsheets, texting engineers, trying to figure out who can cover the emergency callout without missing a compliance deadline.
When Static Optimization Breaks Down
The failure mode becomes obvious in scenarios like this:
→ An engineer finishes a job 40 minutes early.
→ They check their schedule in the CAFM app.
→ Next assigned job is 45 minutes away, starts in 90 minutes.
But there's a job five minutes from where they're standing right now:
→ It's assigned to a different engineer who won't arrive for another two hours.
Both engineers have the right skills. The nearby job is inside its compliance window but getting close to the edge.
Your CAFM platform can't see this opportunity.
It optimized once, assigned the distant job to Engineer A and the nearby job to Engineer B, and that's the plan.
It has no mechanism to continuously re-evaluate assignments as circumstances change, engineers complete work at different speeds, or new reactive work enters the system.
So:
- Engineer A drives 45 minutes to their next job
- Engineer B drives 50 minutes to the job that was five minutes from where Engineer A just was
You've just wasted 90 minutes of windshield time and pushed a compliance job closer to its deadline because your system can't dynamically re-route.
This happens dozens of times per day across a 200-engineer operation. The waste compounds quickly.
Why This Isn't a CAFM Product Flaw
CAFM vendors aren't ignoring this problem because they don't understand it. They're not solving it because it's not what their systems were architected to do.
These platforms were designed as systems of record, not execution engines. They're built to store data, maintain audit trails, enforce compliance workflows, and report on what happened.
Asking CAFM tools to handle continuous re-optimization during live execution is like asking a database to become a dispatch system. It's a fundamentally different problem that requires fundamentally different architecture.
You wouldn't expect your accounting system to also run your logistics. You shouldn't expect your compliance and asset management platform to also manage dynamic execution.
The challenge is that most FM operations don't have anything between their CAFM platform and their field teams.
The CAFM creates the plan, engineers receive their assignments, and planners spend their entire day manually bridging the gap between the static plan and the chaotic reality of live execution.
That gap is where your efficiency disappears.
It's where compliance windows get missed, drive time inflates, and engineer productivity drops despite everyone working flat out.
CAFM Is Essential Infrastructure
None of this means CAFM platforms have failed or should be replaced. They remain essential infrastructure for any FM operation that needs to:
- Maintain statutory compliance
- Track asset lifecycles
- Report on service delivery
You need that system of record.
But execution under live change requires a different layer. Something that sits between planning (where your CAFM excels) and field service reality (where your engineers work).
That layer needs to continuously re-optimize as conditions change, not optimize once and wait for reality to catch up to the plan.
High-maturity FM operations recognize this distinction.
- They use CAFM platforms for what they do brilliantly: maintaining the source of truth.
- They use purpose-built execution systems for what CAFM wasn't designed to handle: adapting to live change in real time.
The Collision of PPM + Reactive Jobs at Scale
Every facility management operation runs on two parallel work streams that fundamentally cannot coexist without friction:
Planned preventative maintenance (PPM) jobs scheduled weeks or months in advance. When it comes to facility management, this includes jobs like:
- Fire alarm testing every quarter
- HVAC filter changes every six weeks
- Elevator inspections on fixed intervals
These jobs are the backbone of compliance, asset longevity, and contractual obligations. You can't skip them without risking statutory failures, accelerated equipment degradation, and penalty clauses.
Reactive work includes jobs like emergency callouts, tenant complaints, equipment failures, and access issues, such as:
- A boiler stops working in February
- A door lock jams at a retail site on Saturday morning
- A leak appears in a server room
This work arrives unpredictably, takes priority by definition, and demands immediate response.
In smaller operations, you can absorb this tension.
But:
When you're managing 30 engineers across a regional portfolio, reactive spikes are manageable. You shift a PPM job, reschedule for later in the week, and move on.
At scale, this collision becomes structural chaos.
What PPM + Reactive Jobs Mix Looks Like for Facility Management at Scale
Here's what actually happens:
Your planner builds next week's schedule on Wednesday afternoon. They allocate PPM work across 200 engineers based on an assumption of roughly 80% availability.
That's reasonable:
You need buffer capacity for reactive work, engineer absences, traffic delays, and job overruns.
Then reality arrives:
→ Over the weekend, six reactive callouts come in. For example, two heating failures, one water leak, three access control issues.
→ Monday morning, your planner opens the system to find eight PPM jobs from last week still unfinished because reactive work bumped them.
→ Those jobs now need to be rescheduled.
But here's the problem:
Compliance windows are hard deadlines.
- That fire alarm test is due by the end of this month for statutory compliance.
- The emergency lighting inspection has a contractual SLA.
- The gas safety check has a legal window.
So now your planner isn't just rescheduling eight jobs into any available slot.
They're trying to fit eight compliance-sensitive jobs into the three remaining windows this month that satisfy engineer availability, trade requirements, site access constraints, and regulatory deadlines.
Most of those jobs won't fit.
They escalate from routine PPM to urgent compliance risk, which means they start requiring overtime slots, weekend callouts, or emergency scheduling at premium rates.
A job that should have cost $120 in regular time now costs $240 because you're paying Saturday rates to hit a compliance deadline.
This cycle runs every single day at scale:
→ Reactive work disrupts Monday's plan.
→ Tuesday brings new reactive callouts and more bumped PPM jobs.
→ By Wednesday, your planner is juggling 15 rescheduled jobs
→ By Friday, the compliance escalation list has grown to 20+ urgent items that need resolution before month-end.
We've watched operations where planners spend 70% of their time replanning work that was already planned, and only 30% of their time actually planning new work.
The job title is "planner," but the actual role is "constant replanner."
What Causes Facility Management Schedules to Break
The root cause of facility management schedules breaking is that fixed schedules cannot coexist with live disruption unless you have continuous re-optimization, not static planning.
Traditional facility management planning treats schedules as fixed artifacts:
You plan the week, publish the schedule, and execute.
But reactive work doesn't respect published schedules. It arrives at 11pm on Sunday, at 6am on Tuesday, during lunch on Thursday. Every arrival invalidates part of your plan.
At 50 engineers, you can manually adjust.
At 500 engineers across multi-region operations, manual adjustment becomes a full-time job for multiple people. And even then, you're always behind. You're reacting to yesterday's disruption while today's new chaos is already forming.
The key thing to understand is:
Facility management operations that scale successfully don't try to eliminate this collision.
They accept that PPM and reactive work will always conflict. And they build execution systems that can re-optimize continuously as disruption arrives, not just once when the weekly schedule is published.
A Breakdown of the Hidden Cost of Missed Compliance Windows
Most facility management operations treat missed compliance windows as a penalty problem:
→ A gas safety certificate runs past its due date
→ You get a $200 fine
→ You book the engineer
→ Job done
→ The compliance team sends a stern email
→ The planner promises it won't happen again
→ Everyone moves on
That framing is wildly incomplete.
The penalty is the smallest line item in the actual cost structure of a missed compliance window.
What really happens when a gas safety check slips past its deadline is a cascading sequence of rework, duplication, escalation, and audit overhead that can cost four to five times the original penalty. It also creates operational chaos that ripples across your entire schedule for days.
Here's what the real cost breakdown looks like when a single compliance job misses its window.
Direct Costs of Missed Compliance Windows
Start with the $200 statutory penalty for the missed gas safety certificate. That's the visible cost, the one that gets reported in compliance dashboards and discussed in monthly reviews.
But now you need to fix it, which means pulling that job to the front of the queue as an emergency priority.
Your planner calls an engineer who's already mid-route on a day of planned PPM work. That engineer either abandons the current job. He wastes the partial work already done and the drive time to get there.
Or:
You dispatch a second engineer as an emergency callout. Emergency callout rates run $150-£200 higher than standard visits because you're paying premium labor rates and disrupting schedules.
There's your first duplicated cost.
If the original engineer gets reassigned, the PPM job they abandoned now needs rescheduling. That creates a second coordination task for your planner, who's already working at capacity.
Rescheduling one compliance job doesn't just mean moving one engineer, but it also means reshuffling the entire day's route to accommodate the priority insertion.
Your planner now spends two hours reconfiguring 15 other jobs across three engineers to make room for the emergency compliance visit without violating SLA commitments elsewhere.
Two hours of senior planner time at $35/hour is another $70.
The three engineers affected by the reshuffle now have suboptimal routes, which adds an extra 45 minutes of combined drive time across the team. At fully loaded engineer costs of $45/hour, that's another $34 in wasted capacity.
You're now at:
$200 penalty + $175 emergency callout premium + $70 planner overtime + $34 route inefficiency = $479
And you still haven't completed the original compliance job.
When the emergency engineer arrives and completes the gas safety check, you've now visited that site twice in the same compliance period. (Once for the missed appointment that triggered the penalty, once for the emergency fix.)
That's a duplicate visit. If the site is 30 minutes away, you've burned an extra hour of drive time at $45, plus fuel and vehicle costs. Add another $60.
You're at $539 in direct costs, nearly three times the penalty itself.
But the cascading effect extends further.
Hidden Costs of Missed Compliance Windows
Because compliance work cannot be deferred, the non-urgent PPM jobs that got bumped to make room for the emergency visit now slide into next week's schedule.
Next week was already at 95% capacity, so those inserted jobs create a bottleneck. For example, two of them miss their own planned windows, which creates future rescheduling work.
The ripple effect from one missed compliance job can disrupt scheduling efficiency for a week.
Then comes the audit burden, which is where the real long-term cost lives.
Compliance audits don't just verify that the gas safety check eventually happened. They verify that you completed it within the statutory window, and they scrutinize your records to assess whether missed windows represent isolated incidents or systemic risk.
If your compliance records show a pattern of missed windows followed by emergency completions, auditors flag your operation as high-risk.
That triggers enhanced oversight, more frequent audits, and in severe cases, remediation requirements that can cost $3,000-$5,000 per incident. This includes consultant fees, documentation cleanup, and management time spent proving you've fixed the underlying process failure.
Total Cost of Missed Compliance Windows
When you add it all up:
A $200 penalty
+$339 in immediate rework costs
+the risk of $5,000 audit remediation if the pattern continues
= $800-$1,000 in direct expenses
(With downstream scheduling disruption that compounds across the estate.)
From a CFO perspective:
Compliance economics aren't about avoiding $200 penalties. They're about avoiding $800 rework loops that erode margin on every contract.
Not to mention, create the kind of systemic execution risk that shows up in audit findings and client retention rates.
Planner Workload vs Engineer Productivity
Here's the paradox that catches most facility management operations by surprise:
As you add planners to improve coordination, engineer productivity drops.
That seems backwards.
More coordination capacity should mean better utilization, clearer instructions, smoother handoffs. Instead, you end up with engineers who spend less time actually working and more time navigating the coordination layer itself.
The mechanism is straightforward once you see it:
Every planner needs information to do their job effectively.
For example:
- Planner A manages mechanical trades and needs ETAs for all HVAC jobs.
- Planner B coordinates site access and wants photos confirming completion.
- Planner C handles parts logistics and requires updates on what's been used versus what's still needed.
Each request is reasonable in isolation, but engineers now spend 45 minutes per day just receiving instructions and reporting status back to multiple planners.
Then there's the waiting:
- An urgent escalation comes in, but which planner owns it?
- The engineer radios in, gets transferred, waits for a callback.
- A site visit wraps up early, but the next job isn't ready because the planner is coordinating a different territory.
Engineers idle while planners coordinate with each other to figure out the next move. That's another 30 to 45 minutes lost daily.
Territory and trade conflicts add another layer:
- One planner says head to Site X because a compliance window closes tomorrow.
- A different planner says Site Y is higher priority because the client is escalating.
The engineer gets caught in the middle, burns 20 minutes clarifying, then drives to whichever site wins the internal negotiation.
Let's put real numbers to this. Take a standard eight-hour workday for a field engineer:
- 45 minutes receiving instructions and reporting back to multiple planners
- 30 minutes traveling between poorly sequenced jobs (because different planners optimized different pieces)
- 60 minutes waiting for parts, access approvals, or clarification on conflicting priorities
- 5 hours and 45 minutes left for actual wrench time
Compare that to an operation where execution is system-mediated rather than planner-mediated. Engineers spend:
- 15 minutes on status updates
- 15 minutes on optimized travel
- 30 minutes on genuine wait time
(parts delays happen regardless of coordination model)
- 7 hours or more for productive work
The difference between 5.75 hours and seven hours of daily utilization is massive at scale.
Across 200 engineers, that's 250 hours of lost productivity per day.
That's the equivalent of 31 full-time engineers you're already paying for but not getting value from.
What Causes Productivity to Drop in Facility Management
The root cause of productivity dropping in facility management is structural.
Each planner optimizes their own territory or trade because that's their job.
For example:
Mechanical gets its jobs sequenced well. Electrical gets its jobs sequenced well. But cross-trade coordination requires planner-to-planner communication, which is inherently slower than system-mediated coordination.
Planner A has to call Planner B to negotiate priority, check if an engineer can swing by a different site, confirm parts availability. Every handoff adds latency.
Human planners are genuinely excellent at judgment calls and handling escalations that require context and experience.
But:
They're terrible at real-time multi-constraint optimization across hundreds of jobs, dozens of engineers, and constantly shifting priorities.
Using planners as the execution layer wastes their most valuable capability on coordination tasks that systems handle better.
You end up with expensive judgment capacity stuck doing low-value routing work, while engineers wait for instructions that should have been automatically sequenced 20 minutes ago.
The inverse relationship between planner headcount and engineer productivity is what happens when you scale a human-mediated execution model past the point where human coordination can keep up with operational complexity.
Why Margins Compress as Facility Management Operations Grow
The economics of facility management operations should work in your favor as you scale:
- Bulk purchasing power improves
- Route density increases
- Negotiating leverage strengthens
A 500-engineer operation should have better margins than a 50-engineer one.
Instead, most FM operations watch margins compress as they grow.
The mechanism isn't obvious from the P&L:
- Revenue grows
- Headcount scales proportionally
- Gross margin looks stable
But underneath that stability, the unit economics of service delivery are quietly deteriorating.
Here are five things that reduce your profit margins when you're scaling facility management operations:
#1 Higher Drive Time
Drive-time inflation is the first culprit. When you're running 50 engineers across 20 sites, average drive time sits around 15 minutes. Reasonable.
At 500 engineers covering 200 sites, you'd expect route density to improve further:
More engineers = Shorter distances between jobs
What actually happens is average drive time climbs to 35 minutes or more.
The problem isn't geographic spread, but execution breakdown.
Job sequencing becomes suboptimal because planners can't process the combinatorial complexity fast enough. Reactive work forces long-distance callouts because the nearest available engineer is already committed.
An engineer finishes a job in Zone A and gets dispatched to Zone D because the system can't resequence fast enough to bundle nearby work.
That 20-minute drive-time inflation, multiplied across hundreds of daily visits, destroys more margin than any purchasing negotiation can recover.
#2 More Duplicate Visits
Duplicate visits compound the problem. Here's a scenario we see constantly:
An engineer visits a site Tuesday morning for a PPM inspection
→ Completes the work, logs it, leaves
→ Two hours later, a different engineer visits the same site for a reactive callout
That's 90 minutes of drive time wasted because the work wasn't bundled.
The reactive job could have been handled by the first engineer if the system had visibility and could dynamically resequence. Instead, you've paid two engineers to drive to the same location on the same day.
Scale that across 200 sites and 500 engineers, and you're funding a coordination tax that grows faster than revenue.
#3 Increased Overtime
The overtime spiral kicks in when schedules slip because compliance deadlines are immovable. This includes gas safety certificates, fire alarm testing, statutory inspections. All of these can't slide into next month.
When reactive work disrupts PPM schedules, you don't get more time. You get overtime.
Overtime becomes the pressure-relief valve for execution failures.
Engineer capacity is fully utilized during normal hours, so catching up on delayed compliance work means paying 1.5x to 2x base rates for evening and weekend coverage.
Those overtime rates destroy margin on the affected jobs.
A PPM visit that should cost $80 in labor suddenly costs $140 because it had to be completed on Saturday.
Multiply that across dozens of delayed compliance jobs per month, and you've eroded quarterly margin targets.
#4 Higher SLA Compliance Risk
SLA risk operates as a hidden margin tax. Most FM contracts include penalty clauses ($500 for a missed response time, £1,000 for a failed compliance deadline), but they're not the real margin killer.
The real cost is maintaining excess capacity to avoid the penalties:
- You keep engineers on standby for emergency callouts.
- You pay premium rates for on-call availability.
- You hold buffer capacity you can't productively deploy because you need it available for SLA protection.
You're paying for capacity you can't fully utilize because the alternative (breaching an SLA) is worse.
That's margin compression disguised as risk management.
#5 Excess Capacity
The capacity paradox closes the trap, because you can't reduce headcount when peak demand requires full capacity.
There are moments when you need every engineer that you have on payroll:
- A compliance deadline week
- A weather event
- A building emergency
But you can't improve utilization during non-peak periods because poor execution leaves engineers underutilized between jobs:
- They're waiting for dispatch
- Traveling suboptimal routes
- Arriving at sites where work isn't ready
- Sitting in traffic because sequencing didn't account for congestion
You're stuck paying for capacity you need sometimes but can't efficiently use most of the time.
The only way to meet peak demand is to accept chronic underutilization during normal operations.
This is why adding more planners doesn't fix margins.
The problem is that human-driven execution can't dynamically reoptimize at the speed and complexity modern FM operations require. Every coordination failure shows up as drive time, overtime, duplicate visits, or excess capacity.
The margin compression isn't a symptom of poor management, but a structural issue of your operation.
Planning vs Scheduling vs Execution in Facility Management
Most facility management operations use these words interchangeably:
- A planner says they're "scheduling jobs", but what they're doing is deciding which engineer has the right certifications.
- A dispatcher says they're "executing the plan", but they're really just communicating it.
- An operations director asks why "scheduling isn't working", when the real breakdown is happening during execution.
This conflation isn't just sloppy terminology, but what makes it impossible to diagnose where your operation actually breaks as it scales.
We've found that facility management planning and execution actually involves five distinct functions that happen in sequence. Each one with different purposes, timeframes, and infrastructure requirements:
Facility Management Planning
Planning is deciding what work needs to happen and who's qualified to do it. You're looking at your PPM schedules, compliance obligations, and reactive requests, then matching them against engineers who have the skills, certifications, and availability.
Output: Work order list.
Example: Gas safety checks need doing, here are the six engineers with Gas Safe registrations who could handle them.
Facility Management Scheduling
Scheduling is deciding when work will happen and which specific engineer will do it. You're taking that work order list and building a week or day plan that assigns specific jobs to specific people.
Output: A structured plan with names, dates, and job sequences.
Example: Engineer A gets the three gas checks in Zone 4 on Tuesday, Engineer B handles Zone 7 on Wednesday.
Facility Management Dispatching
Dispatch is communicating that plan to engineers and confirming they've received it. You're sending job sheets, verifying engineers know where they're going, checking they have the right access codes or keys.
Output: Engineers acknowledge tasks and depart on jobs.
Example: Engineer A has left for their first job.
Facility Management Execution
Execution is the engineer actually doing the work. Traveling to site, performing the task, completing the job. This is where reality diverges from your plan.
Operational reality: Execution is messy in ways planning and scheduling never account for.
Example: Traffic delays someone by 40 minutes. A site contact doesn't show up with access. The part you thought was in the van isn't there.
Facility Management Optimization
Optimization is continuously adjusting the plan based on what's actually happening. An engineer finishes early, so you reroute them to a reactive job nearby.
Output: A dynamically updated schedule that maximizes productivity under real-world constraints.
Example: Traffic delays someone, so you reassign their afternoon appointments. A site access gets canceled, so you slot a different job into that window.
Here's how these functions differ in practice:
| |
Purpose |
Timeframe |
System Type |
Human Role |
| Planning |
Decide what work needs doing and who's qualified |
Weekly/monthly |
CAFM, work order management |
Determine work requirements and resource pool |
| Scheduling |
Assign specific jobs to specific engineers |
Daily/weekly |
CAFM, scheduling module |
Build initial job assignments |
| Dispatch |
Communicate plan and confirm receipt |
Morning of work |
Email, phone, mobile app |
Verify engineers have information and depart |
| Execution |
Perform the actual work at site |
Throughout the day |
Reality (not a system) |
Complete jobs under real-world conditions |
| Optimization |
Adjust plan based on live reality |
Continuously during day |
Route optimization, execution layer |
Respond to delays, early finishes, urgent work |
Why the Difference Between Planning, Scheduling and Execution Matters?
The distinction matters because CAFM and FSM tools handle Planning and Scheduling excellently. They're built for it.
With CAFM and FSM software, you can:
- Manage thousands of work orders
- Track certifications
- Build schedules weeks in advance
- Generate job sheets automatically.
These are systems of record, and they're good at what they do.
But Execution and Optimization require completely different infrastructure.
Execution happens in the physical world, where your carefully built schedule collides with traffic, weather, access issues, and parts availability.
No amount of better planning prevents a site contact from being unavailable or a part from being out of stock. These are execution realities.
Optimization requires live visibility and dynamic re-routing capability that traditional CAFM systems weren't designed to provide.
For example:
When an engineer finishes early, your CAFM doesn't automatically suggest the best next job within 15 minutes of their current location. When traffic delays someone by an hour, it doesn't rebalance their afternoon appointments across nearby engineers.
That requires a different kind of system architecture entirely.
We've seen this play out dozens of times.
An FM operation struggles with productivity and compliance, while their leadership invests in better planning. This comes down to more detailed schedules, more sophisticated work order management, and more planner headcount.
The result is that Planning and Scheduling improve measurably:
- Work order list is cleaner
- Weekly schedule looks more balanced
- Dispatch happens earlier in the morning
But:
- Engineer productivity doesn't increase
- Compliance windows still get missed
- Drive time still inflates
- The operation still feels chaotic
That's because the problem lives in Execution and Optimization, not Planning and Scheduling.
But if you're using the same word for all five functions, you can't even articulate where the breakdown occurs. You just know "Scheduling isn't working!", which leads you to throw more planning resources at an execution problem.
Once you can name these functions separately, you can diagnose where your operation actually breaks.
- If your work order list is incomplete or engineers are assigned jobs they're not qualified for, that's a Planning problem.
- If your weekly schedule is unbalanced or inefficient, that's a Scheduling problem.
- If engineers don't know where they're going or lack necessary information, that's a Dispatch problem.
- If your plan looks perfect but productivity is still low, that's an Execution and Optimization problem.
The infrastructure requirements are completely different for each.
Why Multi-Trade Execution Breaks Linear Systems
Most facility management operations are built on a linear assumption:
Each job is independent → Work happens in the order scheduled → You assign one engineer per job.
Plan Monday → Execute Tuesday → Close Wednesday.
Simple.
That works fine when you're running single-trade operations with flexible access.
But multi-trade FM operations don't work that way.
The moment you introduce trade dependencies, skill constraints, and access windows, linear scheduling collapses under combinatorial complexity.
We've found the breakdown happens faster than most operations leaders expect.
Take a straightforward example: a single site needs three jobs completed this week.
- Electrical compliance test: 2 hours, requires any qualified electrician
- Gas safety check: 1 hour, requires gas-safe certified engineer only, site access limited to Tuesday 9-11am
- HVAC filter change: 30 minutes, any engineer can complete it
You have five engineers available. How many valid ways can you sequence this work?
The first instinct is to say five (one schedule per engineer).
But the actual answer is over 60 permutations, and most of them are invalid.
Why?
- The gas safety check locks you to a two-hour window on Tuesday morning.
→ Only two of your five engineers hold gas-safe certification.
- The electrical test takes two hours.
→ If you send the same engineer for both jobs, they can't complete them both during the Tuesday access window.
- The HVAC work is quick.
→ If the engineer doing it is across town on another job, you've just burned an hour of drive time for 30 minutes of work.
Now you're not just assigning work. You're solving for:
- Skill matching (gas-safe certification)
- Access windows (Tuesday 9-11am only)
- Job sequencing (can these overlap or must they be separate visits?)
- Travel time between this site and each engineer's other jobs
- Bundling jobs into a single visit and seeing if it creates scheduling conflicts elsewhere
One site, three jobs, five engineers, and you're already evaluating dozens of scenarios to find the handful that actually work.
How Multi-Trade Work Breaks Facility Management Operations at Scale
Now scale what we've just explained to 50 sites with 150 jobs across a metro region. You're looking at more than 10^15 possible permutations. No planner can optimize that mentally, even with spreadsheets and color-coded calendars.
This is why hiring more planners stops improving execution. The problem is that multi-trade work creates combinatorial complexity that grows exponentially, not linearly.
Sequencing dependencies make it worse because some jobs must happen in a specific order:
- Scaffolding before roofing work
- Electrical rough-in before drywall
- Fire alarm testing only when the building is unoccupied
You can't run these jobs in parallel. And you can't reverse the sequence without violating safety regulations or site requirements.
Other jobs create follow-on work mid-day. For example:
An inspection finds a faulty component, so now you need a reactive visit scheduled immediately. But that engineer is already committed to three other sites today, or the part won't arrive until Thursday, or the site access window closes at 3pm.
Linear systems assume the schedule you built Monday morning is still valid Monday afternoon.
In multi-trade FM operations, schedules degrade the moment execution starts.
But the real killer is access constraints.
Most commercial and institutional sites don't offer open access:
- Schools limit contractor work during term time
- Hospitals restrict access to critical areas based on patient care schedules
- Retail sites prohibit noisy work during trading hours
- Manufacturing facilities require safety briefings and escort protocols
Suddenly, your 150 jobs don't distribute evenly across the week, but collapse into a few narrow windows:
Tuesday and Thursday mornings, after-hours access only, or first thing Monday before staff arrive.
Now you're optimizing across five engineers and five days, and trying to fit 40 jobs into six available hours, and 12 of those jobs require sequencing, and eight require specific certifications, and three of them might generate reactive follow-on work.
That's why multi-trade execution breaks linear systems. The complexity is multiplicative.
And at scale, it becomes unsolvable without a fundamentally different approach to execution.
What High-Maturity FM Operations Do Differently
The difference between facility management operations that scale well and those that break is about treating execution as infrastructure rather than something planners coordinate manually every day.
High-maturity operations have made a fundamental mindset shift: plans are assumptions, execution is reality.
Execution-First Mindset
High-maturity operations recognize that the schedule is simply the starting assumption and that the real work happens during execution.
This includes situations like:
- An engineer finishes early
- Traffic delays someone else
- A reactive job arrives
- A site becomes inaccessible
The system needs to answer dozens of micro-decisions per hour:
- Which engineer should take this new job?
- Should we re-sequence this engineer's remaining visits?
- Can we still hit that compliance window if we move this PPM to tomorrow?
In high-maturity operations, execution is managed by infrastructure that treats these decisions as optimization problems, not coordination tasks.
Plans change, but the optimization layer ensures they change intelligently rather than chaotically.
Continuous Re-Optimization
High-maturity operations re-optimize continuously every few minutes, not once per day.
When an engineer finishes a job 45 minutes early, the system recalculates their remaining schedule immediately.
That nearby reactive job that just arrived? It gets routed to the engineer who can reach it fastest without breaking compliance commitments.
The schedule stays valid because it adapts to reality rather than pretending reality will conform to the plan.
This creates a fundamentally different operating model:
- Low-maturity planners spend 6 hours per day manually replanning routes, updating engineers, coordinating changes.
- High-maturity planners spend 30 minutes reviewing system-generated exceptions and approving escalations.
The infrastructure handles the constant recalculation. Planners handle judgment calls the system can't make alone.
The productivity difference isn't incremental:
We've seen operations move from 5-6 jobs per engineer per day to 7-9 jobs per day simply by keeping schedules valid throughout the day rather than watching them degrade into chaos by noon.
Planners Supervising Outcomes
Here's the clearest signal of operational maturity: What do your planners actually do all day?
Low-maturity planners coordinate tasks because they're the execution layer, the human infrastructure making thousands of micro-decisions that keep work flowing.
They answer questions like:
- Which engineer should I send to this job?
- Can you move Dave's 2 PM visit to Thursday?
And they do it all day long.
High-maturity planners supervise outcomes by monitor SLA compliance rates, engineer utilization, cost-to-serve metrics.
They also investigate why a particular site keeps generating reactive work, and work with account managers on strategic improvements to service delivery.
Simply put:
FM planners in high-maturity operations handle true escalations and cases where human judgment matters, while technology handles coordination.
- Should this engineer take that job? → The system answers based on skills, location, schedule density, compliance.
- Should we send two engineers to this complex job instead of one? → That's where the planner steps in.
Technology handles the calculable decisions, humans handle the judgment calls.
This is about infrastructure handling coordination so humans can focus on what humans do well:
- Judgment
- Relationship management
- Strategic thinking
- Handling exceptions that require context the system doesn't have.
The difference shows up in your P&L:
- Low-maturity operations add planners linearly with engineer headcount because planners are the execution layer.
- High-maturity operations maintain stable planner-to-engineer ratios even as they scale because infrastructure handles execution and planners supervise it.
When you treat execution as infrastructure rather than as something humans coordinate manually, you get an operation that can actually scale without collapsing under its own coordination overhead.
How COOs Should Evaluate FM Execution Capability
Most facility management operations technology vendors don't show you is what happens at 9am when three engineers finish early, two are stuck in traffic, and a client cancels site access.
That gap is where execution capability lives, and what COOs should evaluate instead of feature lists.
Evaluation Questions
Start with questions that expose how the system behaves under change:
- Can it re-optimize routes in real time when an engineer finishes a job 90 minutes early?
Not replan tomorrow, but reoptimize the next three hours for that engineer and everyone nearby who could benefit from the freed capacity.
- Does it handle multi-trade sequencing automatically?
If a plasterer can't start until the electrician finishes, and the electrician is running late, does the system cascade that dependency through the day's schedule without planner intervention?
- Can it enforce compliance windows as hard constraints during optimization?
If a gas safety check has a 10-day window and today is day nine, will the system prioritize that work even if it creates a suboptimal route?
- How does it integrate with your CAFM?
The system should treat your CAFM as the system of record and sit between planning and field execution. If the vendor pitches their platform as a CAFM replacement, that's a structural misunderstanding of how mature FM operations work.
- What happens live when a reactive callout, traffic delay, or a site access cancellation happens?
Does the system automatically rebalance work across available engineers? Or does it send an alert to a planner who manually rebuilds the day?
Demo Red Flags
Watch for these red flags:
- The vendor cannot demonstrate real-time re-optimization during the demo. They show you yesterday's perfect routes but deflect when you ask them to simulate an engineer finishing early or a job getting cancelled.
- The system requires planners to manually intervene when disruption occurs. If the answer to "what happens when this changes?" is "your planner would handle that," you're not buying an execution layer - you're buying a better spreadsheet.
- The integration story is vague. Claims to integrate with everything, but when you ask for reference customers running it with your specific CAFM, they pivot to "we have an open API."
- The platform is marketed as an all-in-one replacement for your CAFM and FSM stack. Mature operations don't rip out systems of record. They add execution infrastructure that works with what's already there.
Why Proof of Concept Mislead
Proof of Concept projects in facility management operations typically use historical data.
Clean, complete data. Known outcomes. Perfect information. But that's not how real operations work.
Your planners deal with:
- Incomplete job information
- Last-minute scope changes
- Engineers calling in sick
- Clients moving access windows
- Emergency work that blows up schedules
The problem with most PoCs is that success criteria focus on route quality:
Did we reduce drive time by 15%?
Rather than:
System behavior under change.
So, you end up evaluating the wrong thing.
What you need to test is how it responds when an engineer finishes early, when a compliance window closes tomorrow, when three reactive jobs land simultaneously across different sites.
Here's what to test instead:
| |
What to Test |
Red Flag |
Green Flag |
| Real-time re-optimization |
Engineer finishes 90 min early - can system reoptimize next 3 hours for that engineer and nearby team? |
Planner must manually reassign work |
System automatically rebalances and updates affected engineers |
| Multi-trade coordination |
Electrician runs late - does plasterer's dependent job automatically cascade? |
No dependency awareness; jobs stay fixed |
System reschedules dependent work and notifies affected trades |
| CAFM integration |
Does it sync bi-directionally with your CAFM as system of record? |
Vague API claims; no live reference customers |
Named customers running it with your CAFM; clear data flow diagram |
| Disruption handling |
Simulate reactive callout + traffic delay + site cancellation simultaneously |
Planner receives alerts to handle manually |
System re-optimizes all affected engineers automatically |
The best evaluation isn't a PoC with historical data. It's a live pilot with real planners, real disruption, and real consequences if the system fails to execute.
What CFOs Care About in FM Scale
We've found that CFOs typically measure three things when evaluating FM operations:
- Cost-to-serve
- Compliance economics
- Capacity creation
Each tells a different story about whether scale is creating value or destroying it:
Cost-to-Serve
CFOs track:
- Cost-per-job
- Cost-per-site
- Cost-per-asset
As operations scale, these unit costs should decrease. But in most facility management operations, they increase instead.
The culprits are:
- Drive-time inflation as estates spread geographically
- Duplicate visits because jobs weren't bundled properly
- Overtime premiums to hit SLAs
- Excess capacity held in reserve to absorb volatility
An engineer might complete six jobs in a day, but if three required separate trips to the same building, you've paid for nine trips' worth of drive time.
Execution infrastructure changes the math.
- Better engineer utilization means you're paying for productive work, not windshield time.
- Job bundling reduces travel.
- Dynamic re-optimization cuts overtime by preventing late-day scrambles that come from static schedules falling apart.
The difference shows up immediately in unit costs.
An operation running at 65% engineer utilization might see cost-per-job of $180. Push utilization to 75% through better execution, and that same job costs $140. Same work, same engineers, 22% lower unit cost.
Compliance Economics
CFOs often treat compliance as binary:
You either pass the audit or you don't.
But compliance economics are anything but binary.
The visible cost is the penalty: say $200 for missing a statutory inspection window. The real cost is everything that cascades from that miss:
- $800 in rework to reschedule and complete the job
- Audit burden to document the failure
- Margin erosion from emergency callouts to meet the revised deadline
- Relationship damage with the client who now has a compliance gap to explain to their regulator
A single missed compliance window can cost 5x the stated penalty once you account for rework loops. That math makes even small improvements extremely valuable:
If you're running 2,000 compliance jobs annually with a 94% completion rate, you're missing 120 windows. At $1,000 total cost per miss, that's $120,000 in annual waste.
Improve your compliance completion rate from 94% to 95% (Just 1%!), and you've eliminated $20,000 in total costs. Push it to 97% and you've recovered $60,000.
CFOs understand this leverage immediately.
Capacity Creation
CFOs fund headcount growth reluctantly because adding engineers or planners drops straight to the P&L. Execution infrastructure creates capacity without the headcount.
The math is straightforward:
If you're running 100 engineers at 65% utilization, you're getting 65 engineer-days of productive work daily. Improve utilization to 75% and you're now getting 75 engineer-days. That's the equivalent output of 115 engineers, but at a fraction of the cost.
- Hiring 15 more engineers means 15 salaries, 15 vehicles, 15 sets of tools, and the overhead to manage them.
- Improving utilization means better job sequencing, reduced travel time, and fewer schedule conflicts.
You get 15% more capacity at roughly 10% of the cost.
Here's how CFO metrics shift as facility management operations mature their execution capability:
| |
Current State (Low Maturity) |
Target State (High Maturity) |
Economic Impact |
| Cost per job |
£180 |
£140 |
22% reduction in unit cost |
| Compliance completion rate |
94% |
97% |
£60,000 annual waste eliminated |
| Engineer utilization |
65% |
75% |
+15% capacity at 10% the hiring cost |
| Planner-to-engineer ratio |
1:15 |
1:25 |
40% reduction in planning overhead |
The pattern CFOs recognize quickly:
Execution infrastructure converts operational improvements into financial outcomes that show up in the same quarter, not years later.
What IT & Risk Teams Need to Know
When facility management operations leaders propose adding an execution layer, IT and Risk teams often flag it as introducing system sprawl and integration risk. We've found the opposite is true.
When architected correctly, execution layers reduce operational and compliance risk while simplifying your integration landscape.
Integration Safety
The execution layer doesn't replace your CAFM or duplicate master data:
- Your CAFM remains the system of record for asset registers, compliance schedules, and contract obligations.
- The execution layer sits between that system of record and field reality, consuming work that needs doing and returning completion data.
Modern execution layers use REST APIs with webhook-based event streaming, not batch file transfers or legacy screen scraping.
Work orders flow from your CAFM to the execution layer in real time. When engineers complete jobs, completion data (what was done, when, by whom, with what outcome) flows back to your CAFM automatically.
This bi-directional sync keeps compliance records accurate in your system of record while the execution layer handles live coordination - route changes, engineer reassignments, reactive work insertion.
Your CAFM defines the work. The execution layer orchestrates who does it, when, and in what sequence.
Data Flow
Here's what actually moves between systems:
- Your CAFM pushes scheduled PPM work orders, reactive tickets, and compliance tasks to the execution layer daily or in real time.
- The execution layer reads those instructions, optimizes routes based on live constraints (engineer location, skillsets, traffic, site access windows), and dispatches work to field engineers.
As engineers complete jobs, the execution layer captures completion timestamps, status updates, photos, notes, and exception flags.
That structured completion data flows back to your CAFM, updating compliance records and work order histories without manual planner input.
The execution layer reads what needs doing from your CAFM, coordinates execution in the field, and writes results back.
This separation of concerns reduces integration complexity. And your IT team maintains one authoritative data source while gaining live operational control.
Why Execution Layers Reduce Risk
IT and Risk teams understandably worry that adding systems increases exposure. But in facility management operations, manual coordination creates more risk than modern API integrations.
Compliance risk decreases because the execution layer enforces compliance windows as hard constraints during route optimization.
Engineers can't accidentally miss statutory inspections because the system won't allow non-compliant routes. Manual planners can miss these deadlines under reactive work pressure.
Audit risk decreases because completion data flows back to your CAFM automatically, timestamped and structured. Manual data entry by planners introduces transcription errors, delayed updates, and incomplete records - all audit flags. Automated data capture eliminates this exposure.
Operational risk decreases because engineers receive unambiguous instructions (which site, which asset, what task, by when) and the system tracks live location and job status.
This improves duty-of-care during lone working and provides real-time visibility when things go wrong.
Integration risk is lower than you'd expect:
One well-documented REST API integration with your CAFM beats the operational risk of coordination breaking down as you scale.
| |
Current State (Manual Coordination) |
With Execution Layer |
Risk Reduction |
| Compliance Risk |
Planners miss statutory windows under reactive pressure |
System enforces compliance windows as optimization constraints |
Missed inspections eliminated structurally |
| Audit Risk |
Manual data entry introduces errors and delays |
Completion data flows to CAFM automatically |
Transcription errors and incomplete records removed |
| Operational Risk |
Engineers lack clear instructions; location unknown during incidents |
Unambiguous dispatch instructions; live location tracking |
Duty-of-care improved; incident response faster |
| Integration Risk |
Coordination relies on planner memory and spreadsheets |
Single REST API integration with CAFM |
Operational chaos exceeds technical integration risk |
The question isn't whether to add a system.
It's whether manual coordination at scale introduces more risk than a purpose-built execution layer with proper API architecture.
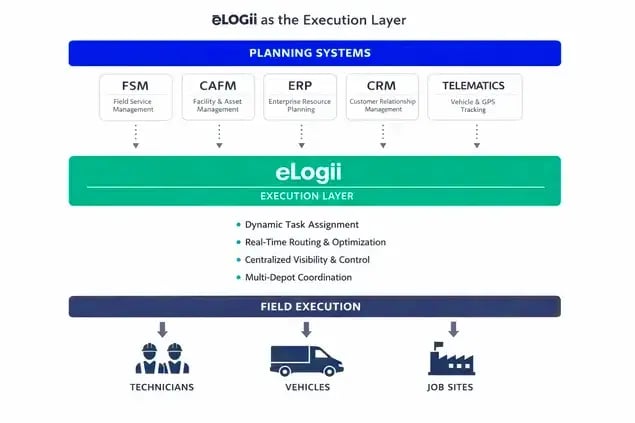
eLogii Is the Execution Layer for Facility Management
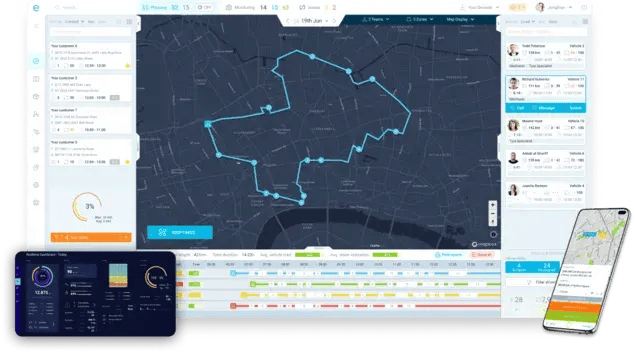
eLogii is the execution layer for facility management. Our software is the infrastructure that sits between your CAFM's perfect plan and the messy reality of field execution. It's the coordination engine that continuously re-optimizes work allocation under live constraints.

Here's why this layer exists:
Your CAFM creates excellent plans assuming work happens as scheduled. It knows what assets need servicing, what compliance windows are closing, what engineers are theoretically available.
But reality doesn't care about your plan:
- Engineers finish jobs early or late
- Reactive work arrives mid-morning
- Traffic delays someone by 40 minutes
- A client cancels site access
- Access codes change without notice
Your CAFM can't respond to any of this in real time. It's a system of record that stores information (what work exists, who's assigned to it, when it's due).
eLogii is what manages resources and schedules tasks moment by moment.

Think of it this way:
Your CAFM is like a database that stores and retrieves information. eLogii is like an operating system that manages resources, schedules processes, handles interruptions, and keeps everything running under changing conditions.
Where the execution layer sits architecturally

An execution layer like eLogii consumes work orders from your CAFM, optimizes routes and schedules under real-world constraints:
- Traffic patterns
- Engineer skills
- Access windows
- Compliance deadlines
- Parts availability
→ Then dispatches work to engineers throughout the day.
→ When jobs complete, it pushes status and data back to your CAFM as the system of record.
It doesn't replace your CAFM, and it doesn't duplicate master data.
eLogii sits between planning and reality, continuously solving the coordination problem your CAFM can't solve because coordination requires optimization under live constraints.
Why this layer becomes inevitable
At small scale (up to 50 engineers), experienced planners can coordinate manually. They know the team, they can juggle changes in their heads, they can text engineers to redirect them when priorities shift.
At 500 engineers across multiple regions and trades, that human coordination capacity gets overwhelmed.
The combinatorial complexity of multi-trade scheduling, the volume of daily disruptions, the compliance risk from manual reassignment breaks human-scale coordination.
That's when execution infrastructure becomes mandatory, not optional.
You can't hire enough planners to manually re-optimize 500 engineer schedules every time reality deviates from plan. The math doesn't work.
What makes this different from just better CAFM

eLogii does three things your CAFM can't do:
- Continuous re-optimization. We're talking every few minutes, not once per day. As conditions change (jobs finish, traffic updates, new reactive work arrives), eLogii recalculates optimal allocation in near real-time.
- Constraint-aware scheduling. eLogii enforces compliance windows, access restrictions, skill requirements, parts dependencies automatically. A compliance-critical gas inspection can't accidentally get bumped for routine PPM. An engineer without electrical qualifications can't get routed to electrical work.
- Live disruption handling. When an engineer finishes 40 minutes early, our facility management tool for execution knows what nearby work they can pick up without creating conflicts downstream. When traffic delays someone, it knows which jobs to reassign and which engineer should take them.
Your CAFM tracks what should happen, while eLogii makes it happen under constantly changing conditions.
That's the difference between a system of record and coordination infrastructure.
Who This Approach Is (and Isn't) For
The execution-first approach to facility management operations isn't universal infrastructure.
It solves a specific problem that only emerges at a specific scale. Being clear about who this is not for increases credibility with those it genuinely serves.
If your operation doesn't match the profile below, that's not a failure. It just means you're either small enough that manual coordination still works, or you've already solved execution at scale through other means.
| |
Not a Fit |
Strong Fit |
| Engineer count |
Under 100 engineers where planner oversight scales linearly |
100-1,000+ engineers where coordination complexity has outgrown manual planning |
| Trade diversity |
Single-trade operations with minimal cross-dependency |
Multi-trade operations requiring sequencing, skills matching, and access coordination |
| Compliance exposure |
Static PPM-only work where everything can be deferred by a week without consequence |
Statutory obligations or contractual SLAs creating hard deadlines and penalty risk |
| Reactive work volume |
Minimal emergency or unplanned work disrupting schedules |
Constant reactive work colliding with PPM commitments and creating replanning overhead |
| Geographic spread |
Single-site or clustered locations with minimal travel complexity |
Multi-site, multi-region estates where drive time and route efficiency materially impact margin |
eLogii is built for multi-trade, multi-site operations managing 100 to 1,000+ engineers where coordination complexity has outgrown manual planning capacity.
It's designed for FM leaders experiencing margin compression despite scale, planner headcount growth without proportional productivity gains, or compliance escalation driven by scheduling failures.
CFOs and PE operating partners looking to improve cost structure and create capacity without adding headcount will recognize the economic logic immediately.
Bottom Line: Execution Infrastructure Helps You Scale FM Operations
If facility management operations break as you scale, it's not because you're poorly run or hired the wrong people. It's structural.
Your CAFM is an excellent system of record. Your planners have excellent judgment. But CAFM tools were never designed for live execution under constant change, and planners can't scale human coordination infinitely.
At a certain scale, execution infrastructure becomes inevitable.
The mindset shift required is straightforward:
Stop treating coordination as labor you solve by hiring more planners. Start treating it as infrastructure you solve with an execution layer that sits between your CAFM's plan and field reality.
For COOs: Evaluate your current execution capability using the criteria we've outlined. If your system can't re-optimize in real time or handle multi-trade sequencing automatically, you have an execution gap.
For CFOs: Quantify the hidden costs in your operation. This includes drive-time waste, duplicate visits, compliance rework loops. If cost-to-serve increases despite scale, execution infrastructure creates capacity without headcount growth.
The operations that scale without chaos treat execution as infrastructure, not overhead. They run continuous re-optimization, supervise outcomes instead of managing coordination, and maintain compliance without heroics.
Explore how execution-first FM operations scale without planner explosion right now:
FAQ about Scaling Facility Management Operations
What is the difference between CAFM and an execution layer in facility management?
CAFM systems store asset data and compliance schedules. An execution layer handles real-time route optimization, dispatch, and disruption response. The execution layer pulls work orders from CAFM, coordinates field execution, then pushes completion data back. CAFM stays authoritative for audits while the execution layer manages the dynamic coordination CAFM wasn't built for.
How do I know if my FM operation needs an execution layer?
Your planners spend more time replanning than planning new work, engineer utilization drops despite hiring more planners, and you're missing compliance windows because reactive work disrupts PPM schedules. You may also need an execution layer if cost-per-job increases despite more engineers and better economies of scale.
If two or more apply, you have an execution gap. Symptoms include planner overwhelm, declining productivity, and rising costs that your CAFM tracks but can't prevent. Operations managing 100+ engineers across multiple trades and sites hit this threshold first.
Can execution layers integrate with CAFM systems or do they require replacement?
Yes, they should. Execution layers integrate with your existing CAFM, they don't replace it. Modern execution platforms use APIs to consume work orders, asset locations, and compliance schedules from your CAFM, then push completion data, time stamps, and job outcomes back after field execution. You need both systems working together: CAFM for record-keeping and execution infrastructure for live coordination under constant disruption.
What ROI should CFOs expect from execution infrastructure in FM operations?
For operations managing 200+ engineers, realistic ROI breaks down across three areas.
A 10-15% improvement in engineer utilization creates capacity equivalent to hiring 15% more engineers at roughly 10% of the cost. You're getting productivity from existing headcount instead of adding overhead.
Reducing drive time by 5-10% cuts cost-per-job by 3-7% through fuel savings and increased billable capacity. Improving compliance completion rates eliminates rework loops that typically cost four times the penalty amount when you factor in duplicate visits, escalation overhead, and audit burden.
Payback period is typically 6-12 months. The ROI compounds because you're reducing structural inefficiency, not just automating tasks.
How do planners' roles change when execution infrastructure is introduced?
Planners shift from manual coordination to supervision. Instead of sending route updates, calling engineers about job changes, or rebuilding schedules after every disruption, they focus on reviewing exceptions, approving escalations, and strategic improvement work.
Their judgment becomes more valuable because they're handling edge cases and complex trade-off decisions rather than routine coordination overhead. This isn't about reducing planner headcount - it's about improving the planner-to-engineer ratio from 1:10 to 1:25 or better. Experienced planners who "just knew" how to sequence jobs now codify that expertise into rules the execution layer applies automatically across hundreds of engineers.
The work becomes more strategic, less reactive, and their expertise scales beyond what human coordination alone could achieve.





