Reactive maintenance has become the daily battleground for field service organizations. Reactive callouts upend schedules, create chaos, and expose deep flaws in how you plan and execute their actual work.
In this article, you’ll learn why planned routes and schedules collapse by mid‑morning once operational complexity crosses a threshold. And what separates organizations that struggle from operators that hold the day together, throughout the day.
You’ll also see why static planning and a calendar‑first mindset don’t work anymore, and why execution‑layer control and dynamic optimization are the only scalable responses.
Here’s an overview of what you can expect to see:
Key Takeaways
-
Reactive maintenance callouts disrupt schedules. Even a single urgent job can cascade through routes causing missed windows, duplicated travel, and frustrated customers.
-
Static route planning and batch scheduling assume stability, but once an urgent service request arrives, schedules collapse, buffers vanish, and manual reshuffling turns into constant firefighting.
-
Mismanaged reactive work drives excess travel time, overtime, missed preventive visits, SLA penalties, and planner burnout. The financial and operational impact is often greater than realized.
-
High-performing operations treat reactive work as a normal input, using real-time prioritization, dynamic re-optimization, and SLA/asset-based rules. Planners supervise outcomes keeping the day under control.
-
You can’t “plan away” reactive maintenance. You must manage it in the field. Execution-first systems like eLogii integrate with FSM, CRM, and ERP tools to balance planned and reactive work in real time.

The Callout That Breaks the Day
You set your plan the night before. You balance workloads. You assign technicians with care. Then the first emergency arrives.
One reactive callout. One asset offline. One irate customer. And everything shifts.
By mid‑morning the schedule is unrecognizable. The map in your FSM looks like a jigsaw someone shook violently.
Reactive callouts reshuffle the entire system.
This isn’t a planning fluke. It’s structural. In a high‑velocity maintenance context, every time a reactive job enters the queue you’re no longer placing work into slots, you’re upsetting an optimized day.
The typical field service day starts stable and linear. Planned work sits in clear sequence. Routes make sense. SLAs and time windows align. Then reactive maintenance jobs arrive unpredictably.
They overwrite priorities. They force unscheduled travel. They push other work later. Before long, your planners are in a constant loop of adjustments, techs are zig‑zagging across territories, and promised windows slip like sand through hands.
This is the point where most organisations feel they’ve “lost control”. They look at their systems and ask: “Why can’t we just fit reactive work in?” The answer is simple:
Because reactive jobs aren’t interruptions. They’re systemic events that can ripple through every dependent decision you made.
Why Reactive Work Is Structurally Different from Planned Work
Planned work behaves. Reactive work doesn’t.
Scheduled inspections, preventive visits, recurring service contracts. These have known timing, clear location boundaries, predictable durations. You can build routes around them.
Reactive maintenance jobs arrive without notice. They have no pattern. They often have higher priority than planned work. They carry SLA escalation mechanics that force attention. They come with customer expectation pressure that refunds and penalties make very real.
In finance‑driven environments, reactive maintenance jobs carry real consequences.
In pest control operations, an urgent can force technicians to abandon planned routes, doubling travel and delaying preventive visits.
In facilities management, a broken HVAC or elevator pulls teams off inspections, creating SLA breaches and frustrated tenants.
In waste management, an unplanned vehicle breakdown or equipment failure can halt collections across depots, triggering overtime and missed service targets.
Reactive work doesn’t fit into schedules, it competes with them.
Where planned work is measured by utilization, cycle adherence, and standard times, reactive maintenance gets measured by response time, first-time fix rate, SLA compliance, and customer retention. These metrics don’t co‑exist peacefully with static schedules.
Planned work is calm. Reactive work is disturbance.
Reactive callouts insert at unknown points in your planned and preventive maintenance schedule. Which means that you can’t forecast job times or location with meaningful precision.
That’s the structural gap.
Reactive work demands priority, but it can’t be forced into a schedule without displacing something else either. When it does, every subsequent planned job is a casualty of that demand.
This isn't a theory. It’s what happens every day in multi‑depot, multi‑region operations with 50+ technicians and a mixed workload.
The Illusion of ‘Fitting It In’
When reactive work hits, organizations respond with improvisation.
“Squeeze this job between visits.”
“Add those two jobs to his schedule.”
“Reshuffle those work orders.”
“He won’t mind the extra drive.”
“Push that job to later.”
“Do it in overtime.”
These seem like reasonable patches to immediate problems. But each choice hides a cost.
-
Squeezing jobs between visits sounds efficient until knock‑on delays ripple through the whole route. A 20‑minute insert becomes a 90‑minute drift by lunch.
-
Pushing work later looks like a neat reprioritisation. But that late slot is already tight. So you push again. And again. By mid‑afternoon, a dozen planned jobs have floated into tomorrow.
-
Overloading technicians feels heroic, until you check utilization data vs actual productivity. Fatigue increases errors. Travel windows get missed. Customer satisfaction falls.
-
Manual reshuffling by planners seems like good old‑fashioned service. In reality, your planners are in “firefighting” mode. And when they patch one schedule at the expense of several others, their local decisions become bad for overall optimizations.
Each of these reactions creates route fragmentation. Instead of a smooth drive from one job to the next, you get a fractured route with multiple returns to central areas, duplicated travel, and cancelled efficiencies.
What’s worse, all of these manual changes bury hidden inefficiencies that compound over time, and across your field service operation. A planner moves one job but doesn’t see three that are downstream, or the delays they have just created for another technician.
The illusion is: “We can manage this with better planning.”
But what you’re doing isn’t planning. It’s absorbing disruption without correcting for it.
Until you separate the appearance of control from real systemic stability, you’re just rearranging deck chairs on a sinking ship.
How Reactive Callouts Cascade Across the Day
Let’s walk through a typical schedule disruption caused by a reactive job.
9:05 AM: A critical reactive maintenance callout hits the queue in the city. A customer’s essential equipment has failed. SLA demands a response within two hours.
Your system flags a nearby technician. That technician is scheduled for preventive visits in a suburban cluster an hour away.
Planner decides to reassign. Tech deviates. Planned visits start slipping.
By 9:45 AM: That technician misses the first SLA time window on a planned call. Customer texts upset.
Meanwhile, a second reactive job arrives. This time in another region. Planner reallocates a technician two assignments removed.
Travel distances balloon. Two technicians are now driving past zones they were meant to serve.
By 11:30 AM: Multiple planned job windows have expired. Planner is on calls persuading customers to accept revised slots. The optimization engine (or calendar tool) shows red flags all over.
Each reactive job didn’t just add seconds. It rewired the day’s entire geography.
Routes and maintenance schedules that are sequenced become disjointed. Multiple technicians cross paths back and forth, while some service zones get neglected until late in the day (if at all).
Planner morale drops. They’re in execution mode, not planning mode.
Field technicians feel it too. They start making tactical decisions on their own: taking a closer reactive job without waiting for dispatch, skipping low‑value preventive work to catch up, calling in late for breaks.
These small choices signal loss of control. They are consequences of a system that’s trying to do dynamic work with static tools.
By lunchtime: The schedule isn’t a plan anymore. It’s a list of planned preventive and reactive maintenance jobs that you failed to complete.
That’s the domino effect:
One urgent job → Reassignments → Missed windows → Duplicate travel → Firefighting
And the next day, you do it all again.
Why Scheduling Tools Can’t Absorb Reactive Change
Traditional field service scheduling software and maintenance planners are powerful in the right context.
They’re built for stability. Batch optimization. Predictable visits. But they assume you’re building a day, not correcting it.
Scheduling allocates work. It doesn’t re‑optimize the day.
Here’s the problem:
Once the software generates the schedule, it doesn’t provide real‑time rebalancing.
Most service scheduling software lets you drag and drop jobs on a calendar but it doesn’t automatically rebalance routes or workloads in response to live change.
The engine that created the plan sits idle while your day dissolves around it:
-
Batch optimization is excellent when your variables are stable. It’s poor when work orders arrive continuously, priorities shift, and SLAs escalate.
-
Static field service planners operate on lists and rules. They aren’t algorithms that adapt to changing inputs multiple times per hour.
So reactive work doesn’t break the schedule because of volume. Reactive callouts break your schedules because static models were never designed for continuous, real‑time change.
What most teams call “dynamic scheduling” is really manual editing. That’s human judgement, not algorithmic optimization.
This is why schedules collapse by mid‑morning:
Your system lacks the capabilities to absorb disruptions. It’s rigid when your day demands flexibility.
But it also means that until you treat day‑of change as a first‑class input, not an exception, your scheduling system will never deliver a stable reactive maintenance schedule.
Hidden Costs of Poor Reactive Handling
The visible pains of reactive maintenance jobs are obvious:
-
Late arrivals
-
Missed preventive visits
-
Angry customers
-
SLA misses
But the hidden costs are where the real damage accumulates.
-
Higher drive time and mileage: When technicians zig and zag across territories because of reactive reassignment, fuel costs spike and vehicle wear accelerates.
-
Lost productive capacity: Time once spent on planned work dissolves into travel and firefighting.
-
Overtime creep: Technicians stretched by unplanned jobs push into overtime just to keep up with the backlog.
For executives and CFOs, these numbers matter.
Overtime isn’t a “nice‑to‑have”, it’s a real line item. Fuel and maintenance costs are measurable.
SLA penalties aren’t abstract either. Lost renewals, rebates, and churn hit revenue and reputation.
Planner burnout ranks high too. Constant manual reshuffling, firefighting calls, and customer negotiations grind morale. You lose experienced planners because the job feels like damage control, not strategy. The turnover for this is staggering.
And perhaps most critically:
The cost of not handling reactive maintenance callouts on time.
Customers remember service failures much better than those jobs that technicians successfully execute. And when you scan the P&L and the balance sheet, these hidden costs show up as operational inefficiency, lower margins, and customer churn.
Yet you rarely link them back to something as simple as how you manage reactive jobs.
Why ‘Better Planning’ Still Fails with Reactive Work
One of the most common responses to issues with reactive job scheduling that we see is telling teams to plan better schedules:
-
You add buffers
-
You tighten travel estimates
-
You increase planned slack
-
You tweak routing constraints
Nothing sticks.
Buffers become phantom capacity. They vanish into the chaos by 10 AM. Tight travel estimates look great on paper, until you insert three reactive jobs into the day.
Over‑planning gives you a false sense of control.
Total productive maintenance thinking is powerful in the right context.
You want to eliminate breakdowns, which is the right long‑term goal. But you also have to realize that you can’t predict or plan reactive work into rigid schedules.
You can’t plan away work that doesn’t respect your plan.
Reactive callouts are emergent events. They reflect equipment failure, customer need, and environmental variables you can’t foresee. No amount of buffers can absorb random job arrivals in the afternoon.
On the other hand:
Reactive maintenance thrives on instability.
That’s why reactive maintenance management requires better execution design and structures that expect change, building reactivity into field operations optimization. (Not into your schedule.)
What Scalable Operations Do Differently
High‑performing field operations don’t fight change. Instead, successful field service businesses embed change into their execution model:
-
Continuous re‑optimization: Routes, schedules, work orders, job sequences, and service times are adjusted and re-adjusted multiple times per hour.
-
Dynamic job priority: A dynamic approach to field service management reshapes real‑time sequences based on live driving conditions, technician status, and SLA urgency.
-
Rules replace manual judgment: Which technician should take this callout? Which job should shift? The answer comes from a prioritisation engine—not subjective debate.
Planners are supervisors of outcomes: Field service planners don’t edit calendars. Instead, they monitor flow, intervene when business rules trigger escalations, and let the system handle continuous reshaping.
In these organizations, reactive maintenance is a variable input that the operational engine expects and absorbs.
They don’t just measure reactive maintenance vs preventive maintenance. They optimize outcomes across both.
They segment reactive work by SLA tiers and asset criticality. A Tier 1 emergency gets immediate dynamic dispatch. A Tier 3 callout fits into the upcoming sequence with minimal disruption.
This prevents unnecessary technician and equipment downtime. And because you’re not rebuilding schedules manually, you preserve the efficiency gains which you spent years building.
Execution‑first teams treat the day as fluid optimization and use field service scheduling software to support them with an execution layer that constantly recalculates the best next action for every resource.
This is how reactive jobs become manageable. Not by resisting change, but by enabling it.
eLogii Supports Effective Reactive Maintenance Execution and Management

Here’s where you should place your thinking when evaluating your current software stack:
Better field service planning tool ✘
Field service execution layer ✔
This is how eLogii supports effective field service management.
eLogii sits above existing systems such as FSM, CAFM, ERP, and CRM.

Importantly, eLogii doesn’t replace this software. Our solution makes them coherent in a reactive world.
eLogii is built for constant same‑day change, absorbing reactive maintenance callouts without blowing up routes.
Instead of a static calendar that planners edit, eLogii continuously recalculates optimal sequences based on live conditions.
Think of it as the operational core that keeps the day together:
-
It balances planned and reactive work in real time.
-
It respects SLA tiers and zones.
-
It minimises travel and preserves productive capacity.
This approach blends proactive scheduling with reactive, real-time control.
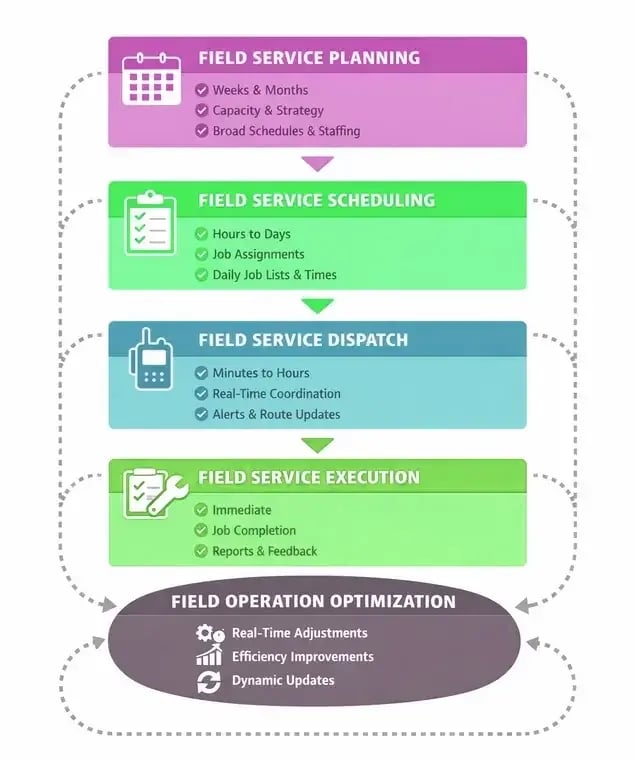
The system continuously reshapes routes and priorities throughout the day, ensuring urgent jobs are addressed on time while other work continues efficiently. Planners supervise outcomes rather than editing calendars, letting the engine manage complexity.
Reactive maintenance jobs don’t feel like emergencies that derail everything. They become inputs the system handles with precision, not panic.
You still deliver inspections, preventive visits, and recurring services. But you do so with less firefighting, less waste, fewer SLA misses, and clearer accountability.
Planned and preventive maintenance schedules don’t collapse when multiple emergency jobs, breakdown callouts, or unscheduled service calls arrive.
SLA tiers and asset criticality guide immediate response, giving teams clear decision-making rules in a high-stakes environment.
Field service technicians spend less time driving along random routes, more time performing productive work, while planners spend more time monitoring their performance.
This is field operations optimization that fits how reality behaves, not how we wish it would.
Who This Type of Reactive Maintenance Management Is (and Isn’t) For
This execution‑first model isn’t a silver bullet for every context. You need to be honest about fit.
| |
Execution‑First Fit
|
Static Planning Fit
|
|
Reactive workload
|
High volume
|
Low volume
|
|
SLA urgency
|
Service Critical
|
Optional
|
|
Team size
|
Medium to large (50+ field technicians)
|
Small teams with <10 technicians
|
|
Geographic complexity
|
Multi‑region, dynamic
|
Simple, fixed
|
|
Volume variability
|
High, dynamic
|
Predictable
|
|
Change frequency
|
Continuous
|
Rare
|
If you’re in a world where reactive jobs are frequent, unpredictable, and costly to mishandle, this approach aligns with your reality.
If your days barely stray from the plan, static scheduling might still suffice — though you’ll still benefit from understanding how change impacts costs.
Bottom Line: Reactive Callouts Don’t Destroy Schedules, Your Current System Is
Reactive maintenance breaks schedules because it represents random, high‑priority inputs that static plans can’t absorb.
Once you pass a complexity threshold, routes unravel by mid‑morning not because of poor discipline or planning, but because your system wasn’t built for real‑time change.
Static planning fails at scale. Execution‑layer control doesn’t.
What stabilises operations is continuous optimization, dynamic prioritisation, and systems designed to absorb reactive maintenance jobs as part of the day.
If you want to manage reactive maintenance without destroying your schedule, you have to manage the execution, not just the plan. And if you want to see how that works with your own data, this is the next step you need to take.



