Field operations optimization is the most effective way to compound efficiency for your business.
At a small scale, achieving this works with almost any system. Whiteboards, spreadsheets, simple FSM tools, even informal knowledge will carry an operation with 5–20 technicians.
At medium scale, discipline and process can compensate.
However:
At large scale with 50, 100, 300, 500+ field staff across multiple regions, depots, and job types, those same methods don’t apply. They break suddenly, and they break structurally.
Most organizations misdiagnose this problem, trying to improve field operations through better planning, more spreadsheets, and greater visibility.
Meanwhile:
-
Operational complexity multiplies as your jobs, field technicians, and regions double
-
Static plans and dashboards can’t adjust in real time to handle growing disruptions
-
Small inefficiencies turn into repeated rescheduling, missed SLAs, reduced capacity, hidden costs, and lower margins
If you manage large, complex field operations at scale, you operate in different realities. And optimizing them isn’t linear, predictable, or easy to control. But it’s still possible to achieve.
How?
Complex field organizations optimize field service execution.
This helps them to bridge the gap between planning and actually completing the work on site. (According to plans and schedules).
Understanding the execution gap, stops you from repeatedly encountering the same failures at high cost and organizational stress each time you want to scale.
While optimizing service execution, simultaneously supports scale that’s predictable, protects margins, and creates sustainable capacity that grows with your operations.
So if you’re an operations leader, enterprise manager, or software decision-makers who oversees 50-500+ field technicians and engineers, this playbook is for you.
If you are responsible for multi-job-per-day scheduling with a mix of PPM and reactive work, you’ll find the insights here invaluable.
And if you’re under high SLA compliance and margin pressure, frequent last-minute changes, cancellations, or emergency jobs, you’ll be able to apply the information directly to how you approach field service optimization.
Here’s a quick summary of what you’ll find in this playbook:
Key Takeaways from the Playbook
-
Complexity in field operations grows exponentially as staff, jobs, and constraints increase, which can overwhelming traditional planning. High-volume, multi-region, multi-job/day operations can't rely on static schedules or linear field service management methods anymore.
-
Static schedules and dashboards give the illusion of control but don't manage real-time disruptions like job changes, cancellations, or engineer unavailability. Execution is what actually drives operational reliability and efficiency.
-
Hidden costs quietly reduce operational capacity and profit margins through excessive drive time, re-scheduling, and planner overhead . Adding headcount or making better plans doesn't solve these financial challenges.
-
Execution is a distinct and essential layer of operations management. It's separate from planning and scheduling that continuously balances constraints and resolves conflicts in real time. Most FSM, CAFM, or ERP systems aren't designed for this function.
-
High-performing operations focus on managing the day, not the plan. They use continuous optimization and rule-based decisioning, where planners supervise exceptions not put out operational fires. Designing for volatility is the structural solution for sustainable performance.

Why Field Operation Optimization Fails at Scale
In complex field operations, the schedule rarely survives past mid-morning.
By 10:30 AM, your schedule is showing its cracks. The plan no longer reflects reality, planners are firefighting, and margin and SLA risk are rising.
To understand why, you have to examine the structural and economic realities of multi-job, multi-region operations with PPM and reactive work.
Static Plans vs. Dynamic Reality
Most operations start the day with a static plan:
-
Phase #1: Planners assign jobs to field engineers and technicians.
-
Phase #2: Jobs are sequenced and routed geographically by location.
-
Phase #3: Jobs are matched to the skills required for each task.
On paper, the plan looks efficient:
- Desired outcome #1: Travel time is minimized.
- Desired outcome #2: SLAs are scheduled.
- Desired outcome #3: PPM slots are allocated.
This is the goal of effective field operations optimization. But reality breaks the plan immediately.
A technician calls in sick, a machine fails, traffic stretches travel and delays service windows. Weather, customer availability, and other human factors create variability that no static plan can absorb.
By mid-morning, these deviations cascade. A two-hour delay for one team or just on one technician’s route can ripple across the entire operation. Engineers fall out of sequence. SLAs are at risk. Planners scramble to reassign jobs.
No matter how carefully you construct it, the static field service schedule becomes brittle.
Daily Replanning Becomes a Necessity
As an experienced operations leader, you know that daily replanning is inevitable. Manual replanning consumes time and drives reactionary work:
-
Planners reshuffle spreadsheets
-
Recalculate skill to job matches
-
Adjust travel times and ETAs
-
Re-optimize routes
-
Re-assign jobs
-
And more
Even small early-day deviations demand disproportionate effort to correct.
This complexity grows exponentially as the number of your field technicians, engineers, and jobs grows.
By mid-morning, replanning turns into survival mode. Every minute a planner spends resolving scheduling conflicts and managing issues in the field is a minute lost from protecting margins, creating additional capacity, or improving processes.
From an economic perspective, a mid-morning disruption in a 100-technician, multi-depot or operation can wipe out the productive equivalent of an entire field tech’s day. Now multiply that across multiple service zones and weeks, and the hidden cost becomes substantial.
Failure Chain Reaction
One delayed job isn’t an isolated situation. Delays trigger chain reactions that can spread across the entire organization.
For example, a technician scheduled for four jobs in a cluster falls behind on all subsequent service visits. Overtime and travel costs rise. SLA windows are missed, potentially triggering penalties or customer dissatisfaction.
In multi-region operations, these ripple effects multiply rapidly.
By 10:15 a.m., three jobs in East London may be delayed due to traffic, one technician has called in sick, and the schedule planner has already spent 45 minutes reshuffling assignments.
Your technicians are effectively executing an outdated schedule on an outdated map. While most field scheduling dashboards only make the problems visible, they DON’T fix them.
Planner Firefighting (Shift from Planning and Optimization to Troubleshooting)
By mid-morning, the planner’s role has shifted entirely from optimization to triaging tasks and managing emergent issues.
This reactive scheduling introduces several hidden costs to your operation:
-
Margin erosion: Prioritising SLA compliance over cost-to-serve increases overtime, travel, and fuel.
-
Hidden capacity loss: Engineers spend more time driving between catch-up jobs, reducing productive work.
-
Burnout and turnover: Planners under constant pressure increase headcount costs and loss of operational know-how.
Firefighting isn’t a failure of skill. Putting out operational fires is a structural inevitability in operations with 50+ field technicians or engineers, multi-job days, and mixed PPM/reactive workloads.
Non-Linear Complexity Trap
Complex field operations are non-linear, where small deviations produce disproportionately large consequences for your organization.
One reactive job may require rescheduling four others, recalculating routes and travel, and updating multiple engineers and field technicians. Human planning assumes linear cause-effect.
But reality multiplies complexity and grows exponentially.
The mid-morning breakdown isn't a flaw in your planning. It is a structural feature of complexity. Any system that separates planning from real-time execution will experience this tipping point.
Planners Can’t Deal With This
The hard truth you need to face is:
Human planners can’t deal with this complexity in real time.
-
Static plans can’t handle operational variables, and even small deviations cascade quickly into large-scale failures.
-
Replanning is reactionary and expensive, and schedule planners are forced into firefighting mode every day.
-
Cascading failures multiply into larger delays, and just one disruption can affect many subsequent tasks, teams, and service zones.
-
Planners that spend time putting out operational fires erode your margins and capacity. Stress, overtime, and hidden costs accumulate.
-
Complexity isn’t linear. Manual, human, or semi-automated field scheduling can’t keep pace with the compounding complexity of operational reality.
By mid-morning, most traditional schedules reflect this. And it’s a predictable, structural failure.
For COOs, CFOs, and IT leaders, understanding this is critical:
Incremental improvements in spreadsheets, dashboards, or static planning will not create new capacity or protect margins. Structural changes that are embedded in execution do.
In fact:
Operations that survive and scale incorporate dynamic, rules-driven execution into their workflows.
And this isn’t optional, it’s an operational inevitability.
Why “Planning Better” Doesn’t Fix the Chaos
A common reflex in field operations is to plan harder.
When schedules break, teams double down: More detailed itineraries, stricter priorities, tighter time windows.
The assumption is: If we plan well enough, chaos will resolve itself.
In practice, this is an illusion that doesn’t work. In fact, it quietly depletes your capacity, margins, and managerial credibility.
Here’s what actually happens:
Planning Reflex
Organisations respond to operational stress by creating plans that are precise on paper.
But in reality, they are brittle and don’t work.
Planners will typically:
-
Allocate tasks by the minute
-
Sequence routes with skill-level matching
-
Pre-empt conflicts before the day begins
And on a dashboard, this looks disciplined.
However:
The flaw is structural.
These plans assume that the real world behaves according to their dashboard. Traffic, skill mismatches, no-shows, equipment downtime, compliance inspections, and same-day reactive work all add variability that you can’t eliminate.
By the time your plan reaches a technician’s device, a part or all of it is already outdated.
Planning harder does NOT reduce operational friction, it exposes it.
Over-Planning Makes Operations Fragile
It may be counterintuitive for you to think, but:
Highly detailed plans reduce operational resilience.
When you plan rigid field service schedules, minor deviations turn into significant issues.
A two-hour delay at one job disrupts multiple downstream assignments, forcing planners to resolve scheduling conflicts.
This is most apparent in operations with 50+ engineers or technicians. Here, operations require them to handle multi-job days across multiple depots and regions, while balancing preventive maintenance (PPM) with reactive tickets.
The complexity and possible combinations of routing, skills, and SLA requirements exceed your human planner’s capacity to manage them manually.
Over-planning gives you the illusion of control while amplifying operational risk.
False Sense of Control
Planners often mistake visibility for influence.
Color-coded Gantt charts, live pins on dashboards, and ETAs provide comfort. They DO NOT provide insight into your operational capacity.
Organizations frequently believe that a well-optimized field service plan equals certainty. In reality, the plan is a snapshot of an unstable system. And the consequences are tangible:
-
Planners and managers are measured by adherence to schedules
-
Planners have no time to protect margins or unlock hidden capacity
-
Engineers and technicians spend more time driving than working
-
SLA breaches appear suddenly rather than predictably
-
Hidden costs mount silently in both margin and labor
In our experience, over-planning can quietly consume the equivalent output of 2–3 full-time staff per week in a 100-engineer operation.
Planning vs. Execution: The Gap Is Wider Than You Think
A plan is a hypothesis. It’s only valid until external factors invalidate it.
PPM schedules, reactive work, skill constraints, and geographic spread interact in ways no static schedule can accommodate.
Manual replanning consumes planner hours and slows decision-making, leaving engineers waiting for instructions.
When planning is treated as a cure-all, the organisation slips into a reactive posture across your entire structure:
-
Planners spend time managing exceptions instead of supervising execution.
-
Engineers get conflicting instructions.
-
Management loses confidence in metrics.
-
Service completion slows to a standstill.
The impact is both operational and economic:
Every rigid schedule shifts time from productive work to travel, eroding capacity and margin.
Economic Reality of Planning Better Schedules
From a cost perspective:
Over-investing in planning without execution control is inefficient.
Each additional planner increases cost without proportionally increasing output. Hidden capacity is lost, SLA penalties accumulate, and operational leverage declines.
Better planning does NOT create capacity. It just shifts the point of failure downstream.
Organisations that manage this gap successfully do not “plan better.” They treat operational execution as a distinct, decision-driven layer.
Instead, you should organize field operations management like this:
-
Field service planners SHOULD supervise operations.
-
Rules SHOULD guide dispatch and routing activities.
-
Schedules SHOULD be optimized around real-time events.
This approach protects your margin, maximizes work-time, and scales without linearly increasing planner headcount.
For smaller, simpler operations, the impact is negligible. For teams with multi-region coverage, 50+ field agents, multi-job days, and SLA pressures, the economic and operational cost is real and ongoing. Especially if your organization combines PPM with reactive work.
PPM + Reactive Work
If you manage a complex field operation, your organization probably lives in two modes at once:
Planned preventive maintenance (PPM) schedules run alongside reactive field service jobs.
This can involve planned and preventive maintenance service delivery through structured PPM scheduling, alongside unplanned jobs and urgent responses to customer demands.
On paper, this mix looks manageable.
Your planners build a monthly preventive maintenance schedule to allocate technicians and engineers to PPM tasks, and insert reactive work into remaining slots. Typically, supported by using some kind of planning and scheduling software.
In practice, this combination puts structural stress on manual coordination.
Simply put:
PPM and reactive jobs break the traditional approach to field service planning and scheduling.
The failure becomes clear when you increase operational complexity and scale beyond 50+ field staff.
Planned + Reactive Work Don’t Scale Together
At scale, PPM and reactive work create rapidly multiplying complexity. It breaks field management systems, because each service carries different planning constraints:
| |
Planned Preventive Maintenance
|
Reactive Service Jobs
|
|
Timing
|
Defined time window
|
Unpredictable ETA
|
|
Location
|
Known in advance
|
Known at arrival
|
|
Service Duration
|
Estimated and relatively stable
|
Unknown until assessed
|
|
Skills & Compliance
|
Pre-matched to known requirements
|
May require scarce or specialist skills
|
|
Priority
|
Scheduled against contractual commitments
|
Driven by urgency and impact
|
|
SLA Characteristics
|
Planned SLA adherence
|
Time-critical, often same-day
|
|
Routing Impact
|
Optimised in advance
|
Forces route reconfiguration
|
|
Scheduling Stability
|
High at start of day
|
Disruptive by nature
|
Attempting to reconcile all of these factors manually using spreadsheets or static field service management tools is like trying to solve multiple sliding puzzles simultaneously, in real time.
This complexity isn’t linear. Adding a single reactive job doesn’t increase workload by one. It can have a ripple effect across multiple routes, field technicians, service depots, and jobs.
Delaying a routine preventive maintenance visit can trigger rescheduling across an entire service zone, undermining SLA performance and margins.
Many organizations underestimate this effect. They assume planned and reactive work are separate streams, which you can manage by layering one atop the other.
In reality, preventive and reactive work are interdependent. Reactive work interrupts PPM schedules, changing routes and travel times, which then disrupts reactive responses.
It’s a feedback loop that compounds pressure until schedule and operational breaking point.
50-Technician Threshold: When Manual Field Operations Planning Stops Scaling
In our experience, field service teams can handle the disruption below roughly 50 field staff (technicians and/or engineers). Beyond that number of employees, manual field operations management fails dramatically:
-
Planner workload increases: Each new technician multiplies routing and prioritisation decisions, making manual planning exponentially more complex.
-
Manual rescheduling consumes planning capacity: Planners spend most of their time triaging tasks and handling exceptions, leaving little room to supervise execution.
-
Route inefficiency grows: Minor delays in reactive jobs ripple across multiple routes and depots, increasing drive-time and reducing schedule adherence.
-
Technician output and performance drops: Field staff spend more time in transit and less time completing billable work, decreasing performance and overall availability.
-
SLA exposure increases: Late reactive jobs and missed PPM tasks accumulate quickly, putting contractual commitments and customer experience at risk.
-
Margin and capacity decline: Operational instability drives hidden costs through overtime, inefficient routing, and lost productivity, directly impacting profitability.
What does this look like in practice?
Consider 100 engineers across three service depots. They’re on a structured PPM schedule with 15–20 visits per engineer per day. Plus a steady inflow of reactive jobs, 1-3 per person.
One late reactive job can trigger hundreds of downstream rescheduling decisions. Human planners can’t evaluate these trade-offs in real time.
This is NOT a planning failure. It’s an execution constraint.
Static schedules that align with the principles of planned maintenance can delay breakdown, but increase operational fragility. Over-planning postpones failure, but it doesn’t prevent it.
Operational Consequences
PPM + reactive work can’t coexist efficiently without dynamic execution control. Every reactive intervention reshapes the operational landscape:
Route inefficiency increases cost-to-serve
-
Minor delays ripple through routes, increasing drive-time
-
Engineers spend more time traveling between jobs vs. performing billable work
-
Overtime rises as teams try to catch up with delayed schedules
Daily service capacity declines
-
Each late reactive maintenance job reshuffles routes and displaces PPM visits
-
A single delayed task can reduce an engineer’s daily output by 5–10%
-
Cumulative effects across depots further reduce operational output
Planner workload becomes structural
-
Continuous rescheduling absorbs planner capacity
-
Teams either hire additional planners or risk burnout and high turnover
-
Decision-making shifts from proactive supervision to constant troubleshooting
SLA performance declines
-
Missed or delayed PPM tasks and reactive jobs compromise contractual commitments.
-
Dashboards, visibility tools, or reporting layers do not prevent delays.
-
Customer experience and compliance metrics degrade despite monitoring.
If your operation runs multi-job days, delivers planned and preventive maintenance, and responds to reactive demand across multiple regions, manual coordination and conventional FSM approaches will not scale.
This pressure is predictable, measurable, and structural.
Recognising this marks the first shift.
Drive-Time vs. Work-Time Problem
At scale, field operations are rarely constrained by the work itself. The real constraint is getting to the job site to do the work.
Every hour a field technician spends traveling is an hour he’s not spending doing billable tasks. This is a hard ceiling on your operational capacity that few organisations measure properly.
This is the drive-time vs work-time problem.
An invisible cost that reduces productivity, margins, and service reliability.
Drive-Time Redefines Productivity
You’re probably aware of traditional service performance metrics:
All of these assume that the job is the limiting factor.
In reality, drive time dominates at scale.
For a 100-technician operation covering 200 sites across three regions, even small inefficiencies in routing translate into thousands of lost engineer-hours per month.
Consider two field technicians with identical skill sets:
Each one is assigned the same number of tasks. One’s schedule requires 4h travel, the other’s 2h. The first technician completes fewer tasks because of routes that aren’t optimised, not his skills or capabilities.
However:
Standard field service KPIs fail to capture this operational factor.
Misdiagnosing this common situation as a problem of individual performance leads to misaligned incentives, burnout, and poor morale among engineers and technicians.
So how much of your employees’ days are genuinely productive?
And how much of them are consumed in transit?
Here’s an operational principle for you:
Work-time is variable. Drive-time is fixed, until you optimize routes and sequence service jobs correctly.
Ignoring this distinction can produce persistent underutilisation of your field technicians and engineers, even in “fully staffed” teams.
Drive-Time Reduces Profit Margins
Drive-time isn’t free. Every hour your field agent spends in transit carries a full set of operational costs:
-
Field technician salary
-
Employee benefits
-
Vehicles use costs
-
Fuel consumption
-
Insurance costs
-
Overhead
According to our experience, field technicians spend 25–30% of their day driving. Over time, this can erode your profit margin, becoming a structural rather than an incidental issue for your organization.
Here’s an example:
A $50/hour field engineer with a full schedule whose day includes 4 hours of driving loses $200 per day in productivity.
Multiply that 50 engineers. Across 220 working days, and the potential revenue loss approaches £2.2M annually.
Now, look at how much you potentially lose based on the size of your team:
| |
Daily Lost Revenue
|
Annual Lost Revenue
|
|
50 field technicians
|
$10,000
|
$2,200,000
|
|
100 field technicians
|
$20,000
|
$4,400,000
|
|
200 field technicians
|
$40,000
|
$8,800,000
|
|
300 field technicians
|
$60,000
|
$13,200,000
|
|
500 field technicians
|
$100,000
|
$22,000,000
|
|
1,000 field technicians
|
$200,000
|
$44,000,000
|
These aren’t hypotheticals. These numbers reflect the structural economics of dispersed field work.
Even modest travel inefficiency scales dramatically in multi-region operations. Lost revenue grows linearly with team size. It’s what makes this invisible cost a multi-million issue for large teams.
But the real question is:
Does your current headcount compensate for drive-time inefficiency rather than planned workload?
Without real-time adjustment to schedules, this hidden cost compounds.
Your organization may hire additional engineers to maintain SLAs, not recognising that the underlying problem is travel inefficiency, not headcount.
Each additional hire increases fixed costs without addressing the root driver of capacity loss. And this creates a feedback loop of escalating costs.
Drive-Time Creates a Hidden Capacity Loss
The impact of drive-time extends beyond profit margins. It constrains the flexibility of your field operations.
This is the very attribute you need to manage same-day changes, reactive work, and SLA compliance. And the problem hits your entire team…
Technicians and engineers stuck on long drives can’t absorb unscheduled tasks or reactive jobs. Field service planners have to deal with incomplete visibility, which creates schedule failures.
Hidden capacity loss caused by drive-time can manifest in three key ways for your organization:
-
Reduced responsiveness: Engineers arrive late to high-priority jobs, threatening SLAs.
-
Unbalanced workloads: Some depots or regions are over- or under-utilised, amplifying overtime or idle-time costs.
-
Skill misalignment: Highly trained engineers may spend disproportionate time driving instead of performing critical tasks.
Even if your planners use advanced field service management software or telematics systems, you can see limited improvement if you fail to optimize the execution layer of your operations.
These systems can record and show location and status, but they can’t inherently resolve the combined problem of sequencing multiple engineers across multiple jobs with minimal drive time.
And this is where your hidden bottlenecks appear: in actual execution in the field.
Economic Imperative: You Have to Address the Drive-Time Problem
The drive-time problem is fundamentally economic, not a tactical or strategic one:
Every hour in the field has a price. Every optimization opportunity has a return.
If you view drive-time as an operational constraint rather than a fixed inevitability, you are on the first step towards protecting your profit margin and creating new capacity for your field service business.
That’s what high-maturity teams do. They make decisions in three dimensions:
-
Work-time maximisation: Ensuring the field technician’s or engineer’s skills are applied to the right jobs.
-
Drive-time minimisation: Sequencing jobs to reduce distance, clustering geographically, and considering real-time conditions.
-
Dynamic adjustment: Continuously re-optimising schedules as new jobs arrive or delays occur, rather than relying on static plans.
Without addressing drive-time at this level, all other operational levers are blunt instruments. This includes planner headcount, SLA targets, and skill assignments.
The result is persistent stress on engineers and planners, with invisible but substantial economic leakage for your organization.
The drive-time vs work-time problem defines the ceiling of what your field operation can achieve.
True operational field optimization doesn't come from dashboards or more hires. It comes from recognising this is a structural constraint. And then, managing it deliberately.
Ideally, you do this by bridging planning and reality with continuous execution-layer optimization.
Planner Headcount Trap
Most field operations hit a predictable breaking point as their complexity grows.
Typically, this happens around 50–60 field staff. Although the threshold can be lower for:
For most organizations the instinctive response is the same: Hire more planners.
On paper, this seems rational:
More planners should reduce fire-fighting and maintain control.
In practice, it rarely works. Here’s why:
What Is the Planner Headcount Trap in Field Operations
Adding field service planners increases capacity on the surface:
Each planner can manage only so many service jobs, schedule exceptions, and unplanned disruptions.
This works for a time. But beyond a certain point, every new hire delivers weaker returns.
Why?
The underlying system remains the same: static schedules, manual/limited optimization, and delayed feedback loops.
The result: Your organization scales its number of planners (or headcount), not operational control.
Planners spend more time reconciling schedules, re-prioritising jobs, and responding to the same exceptions that initially prompted the hires.
The impact: Higher overhead costs with minimal improvements to operational stability or resilience.
Economically, the numbers are stark.
A single planner can cost $60k–$80k annually fully loaded. Hiring three or four more adds $250k–$320k in recurring costs. On the other hand, hidden inefficiencies such as idle field staff, drive-time losses, margin erosion, persist.
Each additional new hire only recovers a fraction of lost planning capacity. This leaves cost-to-serve pressures unresolved.
Organizations often justify the spend as necessary to maintain SLAs. In reality, you’re buying bandwidth to resolve emerging issues, not sustainable control.
This operational trap is reinforced by human dynamics.
Managers assume more planners equals more control (and fewer SLA breaches). However, planners become reactive managers of chaos rather than proactive schedulers.
As the complexity of your operation grows (more regions, depots, customer segments, skill requirements) the mental load on planners rises non-linearly.
Hiring more people doesn’t reduce the mental burden your planners face. It fragments their mental responsibility, which creates inconsistent decision-making, uneven planner utilization, and hidden inefficiencies.
Before adding another planner, ask yourself:
Are we scaling control, or just scaling headcount?
If hiring has become a monthly reflex for field service business rather than a deliberate strategy, your operation is likely stuck in a reactive cycle. This is the core of the planner headcount trap.
How Do High-Maturity Field Operations Approach This Problem
High-maturity field operations approach this problem from a different angle:
They focus on controlling execution intelligently.
This approach to execution requires three key actions:
-
Continuous field operation optimization
-
Rule-based decision-making
-
Dynamic schedule adjustment
A small team of planners can supervise more staff across multiple regions and depots with minimal need for reactive scheduling.
In one 150-field-staff operation, four planners can manage the entire workforce across three regions with little manual intervention. This is impossible with a traditional, static approach to service job scheduling.
As a result, this model releases hidden capacity, reduces headcount costs, and improves SLA adherence.
Planners’ roles transition from resolving urgent issues to supervising active operations:
-
Monitoring performance
-
Prioritising exceptions
-
Identifying systemic bottlenecks
-
Managing technician skills
-
Managing compliance constraints
-
Coordinating cross-region handovers
-
Validating data quality from systems
Field schedule planners remain responsible for resolving emerging issues. But they escalate only exceptions that genuinely require human judgment.
Economically, the effect is twofold:
-
Direct operational cost savings from reduced headcount, and;
-
Indirect operating value from better utilisation and margin protection.
Operations that achieve this rarely do it by chance.
High-maturity organizations rely on an execution layer of field operation management: A system that continuously optimizes schedules, enforces rules, and adapts to real-time change.
Keep in mind, this is not a replacement for FSM, CAFM, ERP, or telematics systems. These tools remain critical for context. But the true solution to the headcount problem is an execution layer.
The planner headcount trap is a structural misdiagnosis.
If you hire more planners, you’re simply paying humans to patch structural inefficiencies. Which can feel like a cure for the problem because it addresses visible symptoms. But without intelligent execution control, each new hire adds cost, complexity, and risk, not capacity.
The real leverage lies in optimising execution, not multiplying intervention.
It's the decision point where most operations break or begin the journey toward high-maturity execution.
Why Visibility, Dashboards, and ETAs Don’t Fix Execution
Here’s a truth of complex field operations:
Managers often lean on dashboards, KPIs, and real-time ETAs to control execution. They assume that seeing everything equates to control.
At first glance, this logic seems sound:
If you know where every engineer is, what every job is doing, and how long each task will take, you should be able to prevent SLA breaches and maintain efficiency.
Experience consistently proves otherwise. And:
Operational Visibility ≠ Execution Management
Here’s why:
Field Operation Visibility vs. Field Operation Execution
Operational visibility only gives you part of the picture. Typically, it tells you what has already happened, or at best, what is likely to happen.
A dashboard can flag a technician running late, a depot short-staffed, or a job at risk. But it cannot close the gap between the current state and the operational outcome you require.
In multi-depot, multi-region operations with hundreds of field staff, the environment is dynamic: customer availability changes, reactive work arises, and work order priorities shift mid-day.
Without mechanisms to act on information, dashboards merely highlight inefficiency, exposing problems without solving them.
Here’s an overview of where operations fail when they rely only on field operation visibility without a layer of execution:
| |
Field Operations Visibility
|
Field Operations Execution
|
|
Operational focus
|
To show what is happening
|
To change what will happen
|
|
Core question
|
What’s going wrong?
|
What should we do about it now?
|
|
Time
|
Retrospective or predictive
|
Real-time and forward-looking
|
|
Output
|
Dashboards, KPIs, ETAs, alerts
|
Execution engines, decision logic, orchestration layers
|
|
Example
|
Technician A is running 45 minutes late.
|
Re-sequence Technician A’s remaining jobs and reassign Job 3 to Technician B”
|
|
SLA consideration
|
None
|
Direct
|
|
Response to same-day changes
|
Highlights disruptions
|
Absorbs and rebalances automatically
|
|
Reliance on planners
|
High (interpretation and manual intervention)
|
Reduced (humans supervise, not intervene continuously)
|
|
Planner role
|
Monitor, escalate, react
|
Oversee, approve, intervene only when needed
|
|
Impact on planner headcount
|
Requires you to add new planners continuously to maintain control
|
Allows you to maintain control without adding new planners
|
|
Scalability
|
Doesn’t scale well with size and complexity, and under real-world conditions
|
Scales well and improves leverage as workloads and operations increase
|
|
Troubleshooting
|
Problems are seen but persist with no systematic change or outcome
|
Adjustments are made explicitly and continuously as conditions change
|
|
Financial impact at scale
|
Makes inefficiency visible; Min. impact on cost-reduction
|
Converts visibility into capacity; Immediate ROI and cost recovery
|
|
Operational outcomes
|
Reactive culture and burnout; Min. capacity and efficiency gains
|
Controlled and stable execution under dynamic conditions
|
Field Service Planning vs. Field Service Execution Management
ETAs, routes, and schedules are forecasts, not methods of control. This is a common mistake that we encounter among field service businesses.
The problem is what happens after your assumptions fail. When you mistake planned outputs for execution control, you create a fragile operation. It looks stable on dashboards, but doesn’t work in real life. The fact is:
Field service planning creates intent. Field service execution management preserves those outcomes.
These are the differences:
| |
Field Service Planning
|
Field Service Execution Management
|
|
Operational focus
|
To create an optimal plan based on known inputs
|
To maintain operational control as reality diverges from the plan
|
|
Core assumption
|
Plan will hold
|
Plan will break
|
|
Time
|
Pre-day or start-of-day
|
All day long, continuous
|
|
Reliance on ETAs
|
Generates ETAs as indicators of plan quality
|
Treats ETAs as fragile signals, not commitments
|
|
Approach to uncertainty
|
Minimize upfront
|
Incorporate and adapt continuously
|
|
Output
|
Routes, schedules, ETAs
|
Real-time job rescheduling, reassignment, task prioritisation
|
|
Response to same-day changes
|
Flag real-time issues or manual replanning
|
Automated or rule-based adjustment
|
|
Planner role
|
Planner creates and maintains plans, schedules, and routes
|
Planner supervises decisions and intervenes by exception
|
|
Impact on planners
|
High workload, constant monitoring
|
Reduced reactive workload, lower burnout
|
|
Troubleshooting
|
Illusion of control when plans and schedules break
|
Explicit adjustments under changing conditions
|
|
Scalability
|
Doesn’t scale well as same-day variables increase
|
Improves leverage as complexity increases
|
|
Impact on capacity
|
Efficient only on paper
|
Recovers hidden capacity in practice
|
|
Financial impact at scale
|
Lost hours, margins diminish when plans break
|
Protects margins and returns through continuous control
|
|
Operational outcome
|
Reactive once disruption occurs
|
Proactive and adaptive by design
|
Real-Time Analytics vs. Real-Time Operational Problem-Solving
Dashboards, KPIs, and SLA reports are critical for performance visibility. They allows you to answer key questions like:
How many jobs were completed on time?
Where is each technician right now?
What is the cumulative SLA adherence?
But real-time and historical analytics don’t prevent failure in complex field operations.
Analytics explain what happened. Real-time problem-solving determines what happens next.
At scale, both are necessary.
But it’s important to understand that operational control doesn’t come from measuring output and performance. It comes from acting on data systematically, while the day is still recoverable.
Here’s the difference:
| |
Real-Time Analytics
|
Real-Time Problem-Solving
|
|
Operational focus
|
Monitor performance, trends, and output
|
Preserve outcomes as reality changes
|
|
Core assumption
|
Seeing the problem is enough to guide actions later
|
Acting immediately is what’s required to control outcomes
|
|
Time
|
Intraday and historic tracking and monitoring
|
Continuous, intraday, decision-driven
|
|
Output
|
Dashboards, KPIs, SLA metrics, reports
|
Dynamic decisions, task reallocation, resequencing
|
|
Insights
|
Descriptive
|
Prescriptive
|
|
Relationship to execution
|
Observes execution after the fact
|
Actively shapes execution in real time
|
|
Example output
|
“SLA adherence is at 92%”
|
“Reassign Job X to prevent an SLA breach at 14:00”
|
|
Planner role
|
Explain or report on performance
|
Control and optimise performance
|
|
Impact on planners
|
High interpretation and manual response
|
Supervision and exception handling
|
|
Response
|
Flag or escalate issues
|
Track and correct issues live
|
|
Troubleshooting
|
Problems are observed but unresolved
|
Adjustments made explicitly under operational pressure
|
|
Scalability
|
Growth is monitored with more dashboards and reports (requires more planners)
|
Operations scale proportionally without more planners (regardless of dashboards or reports)
|
|
Impact on capacity
|
Makes hidden capacity visible
|
Recovers lost or hidden capacity
|
|
Financial impact
|
Supports governance and accountability
|
Protects margin and cost-to-serve
|
|
Operational outcome
|
Limited: Necessary for oversight
|
Direct and immediate: structurally essential to maintain outcomes
|
More Planners, Dashboards, and Better Visibility Isn’t the Answer Anymore
Even at scale, visibility is necessary for field operation optimization. It’s critical for context and reporting. But relying solely on visibility drives operational inefficiencies. Including:
-
Planner headcount inflation: Organizations hire more planners to watch the screens rather than control execution.
-
Reactive culture: Teams respond to alerts instead of anticipating disruption.
-
False confidence: Leadership assumes operational control because metrics exist, while fragility grows unnoticed.
While relying on more planners, tools, and dashboards has its own real consequences:
-
Lost hours
-
Missed SLA compliance
-
Hidden capacity
-
Rising cost-to-serve
-
And more
Execution control doesn’t replace planners or FSM, CAFM, ERP, or telematics systems. But without it, adding planners is just paying humans to patch structural inefficiency. While new software and dashboards without an execution layer are wasted investments.
The next is understanding what execution at scale actually looks like. And how data becomes action, when you create plans and schedules that use real-time decisioning to bridge the gap.
Field Service Planning and Scheduling vs. Service Execution
Complex field operations don’t fail because of technology, people, or poor performance. They fail because organizations systematically treat field service planning, scheduling, and service execution as the same thing.
They are NOT.
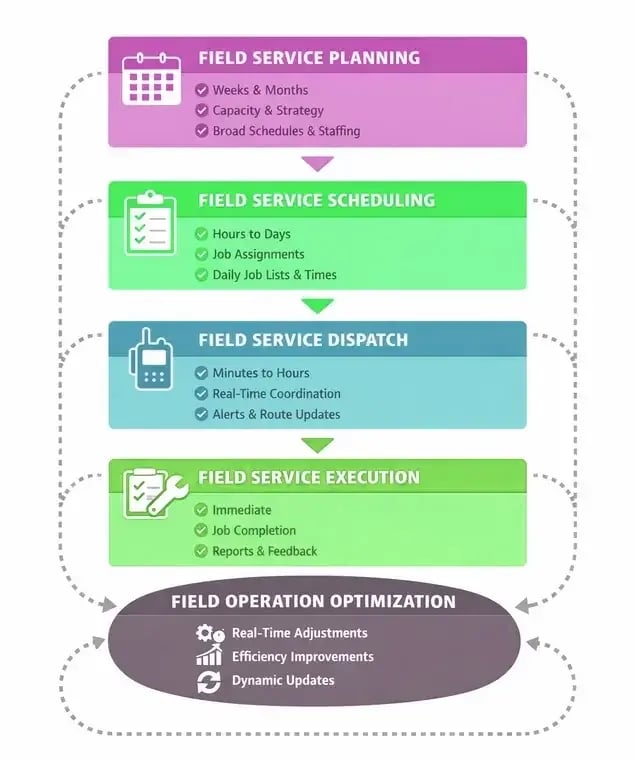
Planning, scheduling, and execution are separate layers of field service management. Despite the fact that they’re usually placed under the banner of field service scheduling.
That’s because most teams assume that optimizing one layer drives improvement across the rest of the operation. Simply improving field schedules or planning better routes doesn’t raise efficiency. Experience shows this.
What does work in practice is understanding how each layer of work affects the other. And how spreading optimization-driven efforts across all three can increase efficiency across the whole operation.
This is how high maturity organizations treat each layer.
Field Service Planning: Contextual Strategy
Field service planning defines the overall shape of the operation over time. It defines capacity frameworks, sets staffing levels, determines service windows, and turns business priorities into operational considerations.
Simply put:
It’s the macro-level, where you strategically assign resources based on how much capacity you need, where it should sit, and what constraints must they operate under.
Service planning answers questions like:
- How many field staff do we need?
- What skills and certifications must we cover?
- Which regions or depots should handle which jobs?
- What service windows are we committing to?
|
Key Characteristics of Field Service Planning
|
|
Timeframe
|
Weeks, months, or fiscal periods
|
|
Objective
|
Ensure capacity aligns with demand while meeting cost, SLA, and compliance
|
|
Output
|
Broad schedules, staff availability, skills matrices, and high-level routing or regional assignments and work order planning
|
|
Focus
|
Resource sufficiency, not minute-to-minute activity
|
Planning is inherently static. It anticipates likely demand patterns, skill availability, and regulatory constraints.
Better planning doesn’t fix SLA breaches or raise operational efficiency. In reality, field services are dynamic environments. Even perfect plans fall through within hours once real work orders, customers, technicians, and engineers enter the system.
Planning provides the context and strategy for operations. It doesn’t enforce adherence in real time.
Field Service Scheduling: Tactical Coordination
Field service scheduling translates the plan into specific, time-bound work assignments. It maps jobs and work orders to specific technicians and engineers, slots, locations, while accounting for constraints such as skills, compliance, drive time, and SLAs.
Scheduling answers questions like:
- Who is doing this job?
- When will it be done?
- How does travel time fit between jobs?
- Does this meet the SLA?
|
Key Characteristics of Field Service Scheduling
|
|
Timeframe
|
Hours to multiple days (weeks in some industries)
|
|
Purpose
|
Make the upcoming work period workable and efficient
|
|
Outputs
|
Daily or shift-level job lists with times and locations
|
|
Focus
|
Making the plan feasible for today or tomorrow
|
Schedules are where plans collide with reality. All field service schedules have to accommodate last-minute changes to plans:
-
Same-day reactive work orders
-
Job cancellations
-
No-access visits
-
Jobs that overrun
-
Technicians calling in sick
-
Traffic, weather, and site conditions
Without field service management software and continuous adjustment, schedules fall apart quickly. Planners then have to spend their day manually moving work, trying to limit damage.
But trying to do all of this at once in spreadsheets or with basic FSM tools creates a fragile system. Once you pass ~50 field techncians with mixed PPM and reactive work, this approach stops scaling.
Key difference from planning:
Field Service Dispatch: Operational Instructions
Field service dispatch turns schedules into actionable, timely instructions for field personnel. Its main focus is to manage communication, adjust schedules and job orders, and confirm work completion according to compliance requirements and SLAs in real time.
|
Key Characteristic of Field Service Dispatching
|
|
Timeframe
|
Minutes to hours
|
|
Objective
|
Ensure field staff receive the right work, at the right time, with all necessary information
|
|
Output
|
Alerts, mobile instructions, and route navigation
|
|
Focus
|
Real-time adjustments to plans and schedules to keep work flowing as conditions in the field change
|
Dispatch is the interface that sits between human decision-makers and operational reality.
When field service dispatch systems don’t work, they’re ineffective. This means that engineers and technicians have to improvise, reducing their output and performance, and increasing error rates.
On the other hand, effective field service dispatching allows planners to supervise operations instead of constantly intervening and troubleshooting issues that come up.
If your planners spend more time moving tasks than completing them, or your field staff routinely deviates from daily schedules, your dispatch layer is likely the weak link in your operations.
Field Service Execution: Where Field Work Actually Happens
Field service execution is the actual, physical completion of the assigned work on location. This includes driving to job sites, carrying out work orders (providing services to customers, fixing systems / equipment, ordering / replacing parts, performing maintenance checks), recording compliance data, observing SLAs, and controlling margins.
|
Key Characteristic of Service Execution
|
|
Timeframe
|
Immediate
|
|
Objective
|
Deliver service, capture accurate operational data, and respond dynamically to disruptions
|
|
Output
|
Completed jobs, captured data, status updates, exceptions, and field feedback
|
|
Focus
|
Reality, not expectation
|
Execution is where the value of your entire field service organization is realised. Or lost.
Without an execution layer that continuously monitors, re-optimises, and feeds back to planning and scheduling, you may experience hidden capacity loss, margin erosion, and SLA breaches.
While most FSM, ERP, or CAFM systems can help you to manage planning, scheduling, and dispatching, this is where they stop.
These software solutions are systems of record, not execution controllers. Expecting them to enforce real-time execution is a fundamental error you should be aware of.
Field Operation Optimization: Continuous Adjustment
Field operation optimization sits across planning, scheduling, dispatch, and execution. Its main focus is to increase operational efficiency by continuously adjusting assignments, schedules, routes, and job sequences as conditions, service requirements, and business goals change.
In doing so:
Field service optimization allows you to maximize resource and capacity utilisation, minimize drive time, and protect margin.
|
Key Characteristic of Field Operation Optimization
|
|
Timeframe
|
In real-time and continuous
|
|
Objective
|
Ensure plans remain feasible and efficient despite constant change
|
|
Output
|
Updated schedules, reassigned jobs, alerts to planners, route and work order adjustments, and recommendations for future planning cycles
|
|
Focus
|
Dynamic decision support across entire operation, not static reporting
|
High-maturity organizations treat optimization as a continuous feedback loop.
For them, this isn’t a periodic exercise where planners continuously fight fires, technicians and engineers treat optimized schedules and routes as suggestions, or failed service calls and SLAs are historical data that will be addressed in the future.
For high-maturity organizations optimization is a chance to stay proactive, and find opportunities to scale operations beyond the current size, complexity, and profitability.
Here, service planners supervise field operations and continuously seek out inefficiencies. Field technicians and engineers execute jobs with clarity and according to SLAs, making sure to provide the best possible service to delight customers and protect the organization’s reputation.
Why Execution Matters for Better Field Service Management
Misaligning these operational layers doesn’t just frustrate your staff. It directly impacts your cost-to-serve and results in:
-
Operational misalignment: Treating planning, scheduling, and execution as interchangeable creates brittle processes that collapse under complexity.
-
Bad investments: Spending on better planning or dashboards without execution control buys visibility, not results.
-
Inevitable breakpoints: Organisations with 50+ field staff, PPM + reactive workloads, and multi-region footprints will hit combinatorial failure unless these layers are respected and integrated into field management.
In organisations of 100–200 field staff, failure to integrate scheduling and execution can reduce productive hours by 10–15%, silently eroding margins.
That’s why understanding these distinctions is the first step in continuous optimization:
| |
Timeframe
|
Purpose
|
Outputs
|
Focus
|
|
Field Service Planning
|
Weeks–months
|
Set capacity, coverage, and priorities
|
Staffing plans, high-level schedules, skills coverage
|
Enough resources in the right places
|
|
Field Service Scheduling
|
Hours–days
|
Assign work orders efficiently
|
Daily field service schedules, job sequences
|
Feasible daily schedule
|
|
Field Service Dispatch
|
Minutes–hours
|
Deliver work and updates to engineers
|
Alerts, instructions, route guidance
|
Staying aligned in real time
|
|
Service Execution
|
Immediate
|
Complete jobs and track field service time
|
Completed work orders, status updates, compliance data
|
Reality of work in the field
|
|
Optimization-Focused
|
Continuous
|
Continuously adjust schedules and assignments
|
Updated schedules, reassigned work, planner alerts
|
Efficiency, utilisation, and margin protection
|
Why Most Field Service Management Software Stops at the Wrong Layer
A persistent pattern in complex field operations is that organisations invest heavily in software.
Despite this, daily chaos remains. And the reason is structural:
Most field service management platforms are systems of record NOT systems of execution.
Understanding this distinction is critical if you’re looking to evaluate technology for multi-job, multi-region operations with SLA, compliance, or margin pressure.
This is what you need to know:
Systems of Record vs. Systems of Execution
FSM, CAFM, ERP, and CRM platforms are primarily recording tools with three underlying issues:
First, they store job data, asset histories, skill profiles, schedules, and compliance information.
Second, they generate dashboards, ETAs, and reports. This creates a single source of truth, but it doesn’t allow you to actively control work or activities that are happening in real time.
Finally, they tell you what happened. And not what should happen next, or what you should do if something unexpected happens.
On the other hand:
Platforms with an execution layer are designed to control and optimize work in real time.
First, instead of observing changing field conditions, they continuously and dynamically adapt to them. This includes adjusting schedules, dispatch work, enforcing rules, and balancing drive-time against work-time trade-offs.
Second, instead treating historical data as a single source of truth, they use systems of record as authoritative context. More importantly, they don’t rely on them to drive execution decisions.
The difference is fundamental:
One system observes, the other system lets you act.
Attempting to manage field service execution using systems of record creates a structural gap:
Visibility doesn’t equal control. Even perfectly accurate dashboards can’t prevent delays, SLA breaches, or margin erosion, which can spill from job to job at any moment and threaten the soundness of your whole operation.
Why Is Execution Missing From Field Service Management Software
There are three reasons that explain why traditional field service management platforms stop at the record layer:
1. Historical Design Bias
FSM and CAFM systems were built to prove compliance, support billing, and report field activities. Planning and scheduling features exist, but they are secondary, often static and rule-light. These systems assume the workday can be fixed in advance. In operations with reactive PPM workloads and same-day changes, this assumption collapses by mid-morning.
2. Combinatorial Complexity
Multi-job, multi-region operations exponentially multiply scheduling constraints. Static or near-static systems aren’t able to take into account routes, skill overlaps, and SLA constraints when creating field service schedules. The result is brittle plans that collapse when the first disruption occurs.
3. Human Bottlenecks
Even with tools and scheduling modules, human planners remain the main execution bottleneck. Dashboards provide awareness, but every disruption still requires human intervention. Planners have to reassign work, readjust routes, and resolve conflicts based on software that “shows the problem” without actually controlling it.
On the other hand:
FSM, CAFM, ERP, and CRM software providers that attempt to provide dynamic features often blur the boundaries between planning, scheduling, and execution. Vendors layer field operation optimization onto record-centric systems, which produces two outcomes:
-
False confidence: Leaders believe they have real-time control, but outputs can’t handle real-world disruptions.
-
Inconsistent execution: Field technicians and engineers improvise, dispatchers troubleshoot emergencies, and planners remain overloaded.
Why Field Service Software Requires an Execution Layer
In large service organisations, the hardest problem is keeping plans valid once work starts. But this is exactly where most field service software stops: at schedules, dashboards, and alerts.
Traditional FSM and workforce management tools allow planners to:
What’s missing is an execution layer: software that can continuously make and apply decisions as reality in the field changes. This includes:
-
Reassign work automatically when jobs overrun
-
Rebalance load when technicians fall behind or surge ahead
-
Adjust routes, priorities, or capacity in real time
-
Resolve conflicts between jobs, skills, SLAs, and job locations (without human input)
Execution-layer software treats plans as starting points, not final results. This keeps work flowing.
Planners are still responsible for handling exceptions, everything else is handled by software. And planners’ role moves from troubleshooting to supervision.
Dashboards, ETAs, and static schedules are still necessary, but they provide the data on which execution control actively runs work in real time.
What High-Maturity Field Operations Do Differently
High-maturity organizations optimize field operations by structuring execution so that routine operational decisions are handled systematically, not manually.
Simply put:
They manage field operations by determining what their human planners should decide and what the software should decide for them.
That’s because they assume variability as a given: jobs overrun, technicians call in sick, traffic spikes, priorities change. Rather than treating these as exceptions, they design their operating model and their software stack to handle and adapt to change continuously.
Field Operations as a Real-Time Control Problem
Low-maturity teams treat scheduling as a planning problem: you create the best possible plan, then react if or when it breaks.
High-maturity teams treat field operations as a real-time control system. The initial schedule is a starting point. What matters is how the system behaves once work is in motion.
In other words, you:
-
Use software that recalculates assignments continuously as jobs start, finish, overrun, or fail
-
Allow schedules to change incrementally throughout the day without human intervention
-
Limit full re-planning to structural changes (major outages, weather events), not routine drift
Schedules aren’t static, they are constantly updated execution states. This is what allows them to operate efficiently whether they have 50 or 5,000 technicians.
Continuous Re-Optimization Is Automated, Not Manual
In high-maturity operations, “re-optimization” doesn’t mean that planners constantly drag jobs around a map.
Instead, their role is to configure the field management software to:
-
Adjust the affected subset of jobs (e.g. the next 2–4 hours of work)
-
Rebalance workloads automatically when technicians fall behind or finish early
-
Recalculate routes and arrival times based on live travel data and job progress
-
Preserve SLA and priority constraints without human micromanagement
Planners aren’t expected to resolve every delay because the system does it by default. Their attention is reserved for decisions that can’t be codified.
Operational Knowledge Is Integrated Into the System Rules and Constraints
High-maturity organisations don’t rely on planners’ knowledge and experience to plan, manage or optimize field operations. They actively turn operational logic into explicit rules and constraints inside their field service management software.
They define, maintain, and evolve rules for:
-
How reactive work pre-empts planned work
-
Which SLAs can be traded off and which can’t
-
Skill, certification, and equipment constraints
-
Geographic and service zone boundaries
-
Assigning jobs based on cost-to-serve vs. revenue
These rules live inside the execution layer, not in spreadsheets or planner’s minds. While the impact is structural:
-
Every planner applies the same logic
-
Decisions are consistent across regions and shifts
-
Improvements persist even when staff change
This is how they scale without scaling planner headcount.
Planners Supervise the System Instead of Running It
Unlike low-maturity teams where planners are the execution engine, in high-maturity teams planners supervise the execution engine. Day-to-day, this means planners:
-
Monitor exception queues, not individual jobs
-
Review only high-impact conflicts surfaced by the system
-
Validate or override edge-case decisions
-
Adjust rules, priorities, and buffers based on observed outcomes
-
Work with operations managers on capacity and demand strategy
They aren’t continuously reassigning jobs. If they were, the system would be considered broken. That’s why this shift changes operational performance, overall:
-
Fewer planners can manage larger, more complex operations
-
SLA adherence stabilises even under disruption
-
Margins improve because inefficiencies are corrected automatically
Metrics Are Tied Directly to Execution Decisions
High-maturity teams measure what the system actually does, not just what it reports. They track:
-
Productive utilization that includes travel, waiting, and idle time
-
Cost-to-serve per job, not just job completion and volume
-
SLA performance under real conditions, not planned schedules
-
Rework and knock-on effects from reactive work
Crucially, they then feed back these metrics into execution logic.
If a depot consistently misses travel estimates, buffers are adjusted.
If a job type routinely overruns, service times are updated.
If a priority rule causes downstream SLA failures, it is changed.
The organisation improves by changing system behaviour, not by blaming people.
Ultimately, high-maturity field operations don’t fight complexity because they manage it structurally. And this is why they perform reliably regardless of size, scale, or operational volatility.
High maturity isn’t about better dashboards or hiring more field service planners, it’s about
using software that actually runs the work to support your teams.
How to Evaluate Field Operations Management Platforms
This is a step-by-step guide for evaluating field operations management platforms. It's based on our experience and those of our users.
It gives you a clear and precise roadmap you should follow when determining whether the software you're currently using can handle execution of your field operations. Or if the tools you're looking to fill that role can actually handle field service execution.
Step #1: Map out the current reality of your field operation
Before assessing any tool, you have to determine the actual complexity of your operations. To do this, you need to assess:
-
Total number of field staff per region/service zone/depot
-
Avg. number of jobs per field technician (PPM + reactive)
-
Geographic coverage and drive-time variables
-
SLA, compliance, and regulatory obligations
-
Dynamic constraints (same-day changes, skill requirements, parts availability)
Step #2: Evaluate functional layers.
To test the strength of a platform, separate planning, scheduling, dispatch, and execution. Benchmark how the software performs in each layer, especially in these use-cases:
-
Planning: Long-range PPM or recurring schedules
-
Scheduling: Dynamic day-to-day sequencing, skills/location-aware
-
Execution: Continuous, rules-based guidance for engineers
-
Re-optimization: Ability to adapt in real-time to cancellations, urgent reactive jobs, and other disruptions
Step #3: Stress-test dynamic replanning.
Using historical data, run simulations with disruptions your planners, dispatchers, technicians, and engineers have encountered on the job:
-
Mid-day job additions or cancellations
-
SLA vs drive-time trade-offs
-
Skill/parts constraint conflicts
-
Cascading changes across depots or regions
Step #4: Analyze the financial impact.
How does the field management platform perform compared to its direct impact on operational costs and profitability. Assess the following:
-
Creating additional operational capacity: Can the same team handle more jobs without adding more planners to the system?
-
Protecting profit margins: How does the software reduce overtime, idle travel, and SLA penalties?
-
Planner efficiency: How much time do planners spend creating schedules and how many hours do they spend troubleshooting emergencies?
-
Aligning functionality to cost-to-serve: How does the software prioritize work that maximizes revenue earned vs. cost-to-serve (dollars per job)?
Aim for capacity gains equivalent to one additional field technician per depot (at least). Or profit margin improvement that can offset the platform cost within 12 months.
Step #5: Verify that the software can integrate with your tools.
Execution-layer platforms must work on top of your existing systems (FSM, CAFM, ERP, CRM, telematics).
To do this, pull data from your current software, and then try to push actionable guidance to field technicians and planners. Then try to see whether the software can maintain service execution under a full operational workload.
Step #6: Identify any red flags.
Early warning signs of operational failure include:
-
Reliance on manual overrides for mid-day changes
-
Dashboards/reports without execution control
-
Claims of AI autonomy without rules-based logic
-
Software demos built on simplified or curated datasets
Step #7: Run a 2-week shadow test using the software.
Running a pilot using real operational data is the fastest way to justify and validate ROI, and:
-
Simulate live operational disruptions
-
Define KPIs aligned with SLA compliance, drive-time efficiency, and capacity utilization
-
Compare planner workload and operational throughput pre- and post-platform
-
Quantify capacity creation, margin protection, and headcount impact
-
Confirm continuous field service optimization is feasible in practice
Step #8: Share results with other decision makers.
Following the test for 1-2 representative depots, measure capacity utilization gains, profit margins, and planner workload for that period. Then share the results with finance and IT to address any concerns and accelerate approval cycles.
Execution Layer Explained: How eLogii Helps to Optimize Field Operations via Execution Control
Field service organizations today rely on multiple enterprise systems:
-
ERP platforms manage inventory, finance, and procurement
-
CRM systems manage customer relationships
-
CAFM or FSM software helps plan preventive maintenance and track assets
-
Telematics monitor vehicles and driver behavior
Individually, these tools provide value, but none directly control execution in the field.
Schedules generated in FSM systems can quickly unravel when reactive jobs appear, technicians are delayed, or depots have constrained resources.
This gap is precisely where eLogii sits.
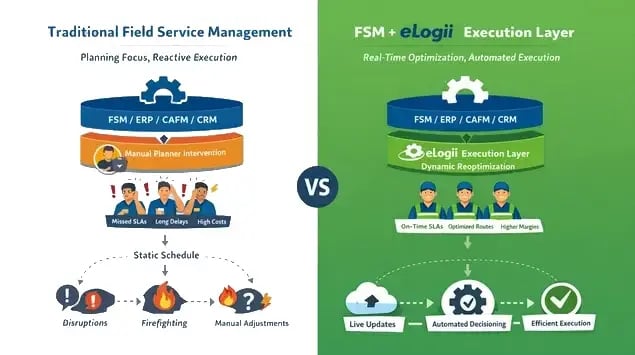
eLogii exists to provide the execution layer: the bridge between planning and real-world field operations. It takes the outputs of ERP, CRM, FSM, CAFM, and telematics and translates them into actionable, dynamic workflows for technicians.
It monitors progress in real time, adapts to emerging conditions, and ensures that the plans generated in upstream systems are carried out efficiently, accurately, and predictably.
Without an execution layer, even the most sophisticated planning systems leave organizations exposed to operational volatility.
As organizations scale across multiple depots, regions, and hundreds of technicians handling a mix of preventive and reactive work, execution control is no longer optional, it's inevitable.
Where eLogii Fits Within Field Operation Optimization
eLogii exists because traditional enterprise and field service systems are designed for planning, monitoring, or reporting, not real-time execution. FSM, CAFM, ERP, CRM, and telematics platforms provide valuable data and structure, but they lack the mechanisms to:
-
Dynamically assign work in real time based on location, skill, and availability
-
Rebalance multi-depot resources across regions as conditions change
-
Adjust routes and schedules on-the-fly to accommodate urgent jobs or traffic
-
Provide centralized visibility into the execution of every field task
In other words:
Organizations can plan meticulously, but without execution control, those plans rarely translate into efficient field performance.
eLogii exists to fill this gap, ensuring that the work gets done as planned, or it adapts intelligently when conditions require changes.
Where Does eLogii Sit Within the Field Service Management Software Stack
eLogii occupies the execution layer, sitting between upstream systems (ERP, FSM, CAFM, CRM, telematics) and downstream field activity (technicians, vehicles, job sites).
Upstream systems provide the what, when, and who: the plan, the resources, the assets. eLogii provides the how and now: translating plans into actionable, optimized execution workflows.
-
FSM/CAFM/ERP/CRM: Define strategy, schedules, resources, and customer requirements
-
eLogii Execution Layer: Assigns work dynamically, optimizes routes, balances resources across depots and regions, and ensures SLAs are met
-
Field Execution: Technicians receive tasks with real-time instructions, routing, and updates; you monitor progress that's fed back into the system
This positioning allows you to leverage existing technology investments while closing the critical gap between planning and actual service delivery. eLogii doesn't replace upstream systems; it amplifies them.
How Does eLogii Optimize Field Service Execution
In complex field operations, execution is where efficiency and customer satisfaction are won, or lost.
If you manage 50+ technicians across multiple depots, handling both PPM and reactive jobs, you probably face constant operational friction:
- Planned schedules conflict with unplanned reactive work
- Travel time and logistics inefficiencies erode productivity
- Skills, vehicle capacity, and parts availability constrain assignments
- Multi-depot, multi-region coverage introduces coordination complexity
eLogii provides control over these dynamics.
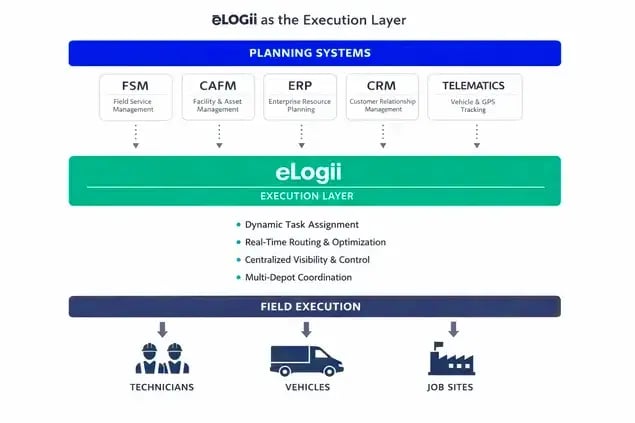
The platform continuously monitors field conditions, dynamically assigning and reassigning work to optimize productivity. Real-time routing accounts for time windows, traffic, and resource constraints. Multi-depot operations are automatically balanced to minimize downtime and ensure workload equity.
Visibility is another key advantage.
eLogii gives operations managers a live view of all field activity, across depots and regions. Job completion, SLA adherence, and technician progress are tracked in real time, allowing managers to intervene immediately when delays or exceptions occur. This transforms decision-making from reactive to proactive.
Why Execution Software Is Inevitable
For modern, complex field service operations, execution software isn't optional anymore. Manual dispatch, spreadsheets, and static schedules can't scale, or respond to unplanned work, dynamically optimize multi-depot operations, or provide real-time visibility into field activity.
Execution-layer software like eLogii makes the difference by:
- Ensuring reliability: PPM and reactive work are executed according to plan while accommodating real-time changes
- Maximizing efficiency: Routes, assignments, and resources are continuously optimized
- Providing transparency: Managers see every job, every technician, every depot in real time
- Enabling scalability: Multi-region, multi-depot operations run smoothly without adding manual overhead
Ultimately, eLogii closes the execution gap left by FSM, CAFM, ERP, CRM, and telematics. Without it, upstream systems cannot fully deliver their intended operational benefits.
With eLogii, field operations become predictable, measurable, and optimized. If you're seeking to scale, improve customer service, and maintain operational control, execution software isn't a luxury anymore, it's inevitable.
Who This Approach to Field Service Execution Is (and Isn't) For
This approach is deliberately narrow. It is designed for operations where traditional planning and FSM tools fail under real-world complexity. Understanding whether this applies to you is critical: if your operation does not meet multiple criteria below, continuing may waste time.
| |
Right For
|
Benefit / Pain
|
Isn’t Right For
|
|
Team Size
|
50–500+ field staff
|
Avoid combinatorial overload; reduce planner burnout
|
<50 staff
|
|
Geography / Depots
|
Multi-region, multi-depot
|
Gain visibility and control across distributed operations
|
Single site, low geographic spread
|
|
Job Mix
|
Multi-job-per-day, mixed skill requirements
|
Protect margins by optimising work-time vs drive-time
|
Single-task, single-job-per-day
|
|
Work Type
|
Planned (PPM) + reactive mix
|
Maintain SLA compliance despite dynamic demand
|
Purely reactive or purely scheduled work
|
|
Constraints
|
SLA-, compliance-, or margin-constrained
|
Prevent costly service failures and regulatory breaches
|
Low-pressure operations; failure tolerable
|
|
Workforce Setup
|
Home-based or distributed teams
|
Increase planner effectiveness; reduce firefighting
|
Centralized or depot-based teams with low variability
|
|
Volatility / Change
|
Frequent same-day rescheduling
|
Retain capacity and protect margins despite chaos
|
Stable schedules, low day-of volatility
|
|
Operational Goals
|
Capacity creation, margin protection, planner burnout reduction
|
Unlock hidden capacity and efficiency gains
|
Expecting automation to “fix” planning without process change
|
|
Complexity Threshold
|
High combinatorial scheduling complexity
|
Avoid structural bottlenecks that kill productivity
|
Low-complexity operations
|
If you tick several boxes above, ignoring execution-layer thinking means ongoing hidden profit loss, planner stress, and SLA misses.
And in all likelihood, engaging with this framework isn't optional for you anymore. It's the only way to manage complexity without continuously putting out operational fires.
Bottom Line: Field Operation Optimization Requires Your Organization to Shift ItsThinking
If you're looking to optimize your field service operations, there are three truths that are unavoidable for you:
-
Static plans fail by mid-morning. Real-world disruptions always outpace rigid schedules.
-
Visibility does not equal action. Dashboards show what happened, not what should happen next.
-
Planner headcount cannot scale linearly. Adding planners increases cost without creating meaningful capacity.
This isn't a planning or scheduling problem, it's an execution problem. True optimization exists where real work happens: in continuous, real-time operational control of jobs, skills, and resources.
And if you manage 50+ field technicians or engineers, with a multi-region, multi-depot footprint. handling PPM and reactive work, under SLA, compliance, or margin pressure, then you need to adapt your mindset from planning to execution.
If you don't, you're going to fail in all too predictable ways:
-
Planner firefighting: 50–70% of daily effort spent reacting instead of supervising.
-
Combinatorial chaos: Multi-job-per-day schedules with PPM plus reactive work create exponentially complex planning.
-
Hidden margin erosion: Inefficient routing, misaligned skills, and drive-time reduce usable capacity.
Software misalignment: FSM, CAFM, ERP, and telematics systems provide records but not execution control.
So ask yourself:
-
Are your planners firefighting more than supervising?
-
Do static plans fail by mid-morning?
-
Are there hidden capacity losses from drive-time or routing inefficiency?
If yes, your operation is ready for execution-layer adoption. And take the first step in true field operation optimization.




