PPM scheduling looks reliable until reactive jobs, delays, and real-world constraints collide with your plans.
In other words: static planning and manual scheduling only work on paper.
When you apply them to your actual field service operations, they fail spectacularly.
This article explains why you can’t control planned preventive maintenance (PPM) schedules and reactive maintenance once your operation grows beyond 50 technicians.
You’ll see how daily disruption, skills, SLAs, drive time, and overruns create complexity that spreadsheets, calendars, and traditional FSM tools can’t handle.
We’ll also break down what actually happens during a typical day, why adding planners doesn’t fix it, and what scalable operations do differently.
If you manage PPM and reactive work at scale, this guide will help you regain control, reduce cost, and protect service performance throughout.
Let’s take a closer look at what else you’ll find in this useful guide:
Key Takeaways
-
PPM scheduling works at small scale but becomes unmanageable once operations exceed ~50 technicians due to exponential complexity and continuous reactive demand.
-
Manual planning, spreadsheets, and even FSM calendars fail under high cognitive load, making errors, missed appointments, and route inefficiencies inevitable.
-
Adding planners or tightening processes only increases cost and coordination overhead without restoring real-time control.
-
Static FSM tools can't handle continuous change; batch optimization and fixed schedules break down under combined preventive and reactive workloads.
-
Scalable operations succeed by treating schedules as starting points, continuously re-optimizing work, enforcing rules consistently, and supervising outcomes rather than micro-managing tasks.
The Moment PPM Stops Being “Predictable”
PPM scheduling looks predictable on paper. Preventive visits are booked weeks ahead. Routes are optimized. Technician capacity appears balanced. Everything fits neatly into a calendar.
Then the day starts.
Unexpected schedule changes happen almost immediately. A breakdown call arrives. A technician reports a delay. A site isn’t accessible. A part is missing. Another job takes longer than planned. Someone calls in sick. By mid-morning, the plan is already compromised.
This is normal in field operations. And that is precisely the problem.
Planned preventive maintenance schedules assume stability. The real world delivers variability. Reactive maintenance doesn't politely wait until tomorrow. SLAs override intent. Safety and compliance override convenience. Customers override routes.
At small scale, this mismatch feels manageable. Shift changes can absorb disruption. Planners prioritize the most important calls first. Reactive maintenance schedules feel “handleable” because there is enough slack in the system to improvise.
PPM schedules look tidy when you have 10 or 20 technicians. Even with interruptions, a human planner can still rebalance work mentally. Whiteboards get updated. Spreadsheets stretch a little further.
Somewhere around 50 field technicians, this stops working.
Not because people become less capable. Not because planners are poorly trained. But because operational complexity crosses a threshold. The volume of preventive and reactive maintenance overwhelms static planning. Chaos isn’t caused by bad execution. It emerges from the system itself.
This is the moment where scheduling is no longer about creating plans. It becomes about surviving constant change.
What PPM + Reactive Maintenance Really Looks Like at Scale
At scale, preventive and reactive maintenance doesn't resemble a clean planning exercise. It resembles a live system under constant pressure.
Preventive visits are booked weeks or months in advance. These are often regulatory, contractual, or compliance-driven. They must happen within defined windows. Miss them, and penalties follow.
Reactive jobs arrive continuously. Breakdowns, faults, customer escalations, safety issues. They arrive unpredictably. They demand immediate attention. They rarely align with the existing plan.
SLAs override “the plan” every day. A reactive job with a four-hour response time instantly outranks a planned visit scheduled for today. The ppm maintenance schedule becomes negotiable the moment uptime, safety, or customer impact is at risk.
Skills and compliance constraints further limit flexibility. Not every technician can do every job. Certifications, authorizations, asset familiarity, and regulatory requirements matter. You can't simply move work to “any available person”.
Customer time windows constrain routing. Access may only be allowed at specific hours. Some sites require escorts. Some locations can't be visited back-to-back. Every constraint reduces optionality.
Geography compounds the problem. Multi-region, multi-depot operations introduce travel time, cross-border rules, vehicle availability, and depot capacity. Route optimization is fragile when geography is large and variability is high.
The outcome is unavoidable.
You are no longer scheduling work. You are constantly trading off priorities.
Every decision sacrifices something else: cost, service, compliance, technician wellbeing, or customer experience.
Static ppm schedules aren't wrong. They're simply insufficient for the reality that you expect them to control.
Why Manual PPM Scheduling Works… Until It Doesn’t
In early growth stages, manual planning works surprisingly well.
Spreadsheets and whiteboards provide visibility. Calendars in FSM tools show technician availability. The number of jobs is small enough to reason about. Exceptions are memorable. Planners know technicians personally and understand their preferences, strengths, and weaknesses.
At this scale, planners really can “hold it all in their head”.
FSM calendars feel sufficient at first because they present a clear, static picture. Preventive visits sit neatly alongside reactive work. Drag-and-drop rescheduling appears to solve disruption.
This creates a dangerous illusion: that more discipline, better training, or tighter processes will preserve control as the operation grows.
The breaking point isn't gradual. It's abrupt.
The precise moment cognitive load breaks is when the number of simultaneous variables exceeds what a human can reason about reliably. This happens long before 100 technicians. For most operations, it happens around 40–50 field service technicians or engineers.
Why?
Because complexity grows non-linearly. Each additional technician doesn't add one more variable. They multiply interactions between jobs, routes, skills, SLAs, inventory, and geography.
No amount of training fixes this. You can't train the human brain to calculate thousands of trade-offs in real time while under pressure. And you can't expect your planners to simulate alternative future scenarios continuously throughout the day.
When planners make mistakes at this scale, it isn't incompetence. It's physics.
Teams aren't to blame for missed appointments, double bookings, or inefficient routes. The system they're operating within is no longer designed for the problems they're facing.
50-Technician Threshold: Where Operational Complexity Explodes
The 50-technician threshold isn't symbolic. It reflects a fundamental shift in mathematical and operational reality. This is the point where field operations move from being complicated to being complex.

Below this threshold, variability exists but remains containable. Above it, variability compounds faster than human planning can absorb.
Exponential Increase in Scheduling Complexity
At small scale, scheduling is largely linear. Add one technician, add a small amount of complexity. Add one job, adjust a route.
Beyond roughly 50 technicians, complexity becomes non-linear.
Each job can theoretically be assigned to multiple technicians. Each technician can perform multiple jobs in different sequences. Once routing, skills, time windows, SLAs, depot constraints, and shift rules are introduced, the number of possible job-to-technician combinations explodes.
This isn't incremental growth. It's exponential.
Planners are no longer selecting between a few reasonable options. They are operating in a decision space with thousands—or millions—of possible permutations. Most of those options are invisible. Many are subtly wrong. Some look acceptable now but fail hours later.
At this point, “experience-based” planning breaks down. No human can reliably evaluate that decision space in real time, regardless of training or effort.
Operational Uncertainty Becomes the Default State
At scale, uncertainty is no longer an exception. It becomes the operating condition.
Travel times vary due to traffic, weather, access restrictions, and site conditions. Job durations are estimates influenced by asset condition, customer readiness, and technician familiarity. Reactive maintenance arrives continuously and unpredictably.
Planned preventive maintenance schedules assume a level of predictability that simply doesn't exist in large, real-world operations.
When uncertainty is occasional, static ppm schedules can absorb it. When uncertainty is constant, static plans degrade immediately.
The plan stops being a guide and becomes a liability.
Jobs Grow Faster Than Capacity
As operations scale, the number of jobs increases faster than technician headcount. Preventive workloads alone can fill most available capacity. Reactive maintenance consumes the remaining slack.
Once slack disappears, every disruption matters.
There is no buffer to absorb delays. No spare capacity to rebalance quietly. Any deviation forces a visible trade-off between cost, service quality, compliance, or technician wellbeing.
This is where ppm and reactive maintenance collide most aggressively. Preventive work protects long-term asset health. Reactive work protects immediate uptime. The system must constantly choose which risk to accept.
Static scheduling can't make these decisions fast enough or consistently enough.
Variable Service Duration Breaks Linear Thinking
Service duration is one of the most underestimated sources of complexity.
At small scale, a 15–20 minute overrun feels trivial. At scale, it's destabilizing.
A small delay early in the day propagates forward. It pushes later jobs outside customer windows. It increases drive time as routes are adjusted. It forces planners to intervene manually. It increases the likelihood of overtime or missed appointments.
Because multiple technicians are affected simultaneously, these overruns interact with each other. What would be manageable in isolation becomes unmanageable in combination.
The system doesn't fail catastrophically. It degrades gradually, then suddenly.
The "Domino Effect" Becomes Systemic
At this scale, delays are no longer local problems. They become systemic.
One late job causes a missed appointment. That missed appointment requires rebooking. Rebooking compresses future capacity. Preventive work is postponed. Asset risk increases. Reactive demand rises. SLAs tighten further.
Tomorrow’s ppm maintenance schedule starts under pressure before the day even begins.
This feedback loop is self-reinforcing. The harder planners work to “fix” it manually, the more fragile the system becomes.
What looks like a planning problem is, in reality, a systems problem.
The organization has crossed the point where static scheduling and human coordination can keep pace with operational complexity. Control isn't restored by working harder, planning earlier, or adding more spreadsheets.
It requires a different way of executing work in real time.
PPM + Reactive Maintenance Schedules: Daily Re-Planning Loop
To understand why ppm and reactive maintenance break static schedules, it helps to follow a single, ordinary day. Not an extreme failure. Not a crisis. Just a normal operating day once field operations pass meaningful scale.
Morning Plan: Order Before Reality Arrives
The day starts with a plan created the night before or early that morning. Preventive visits are placed carefully across technicians. Routes are optimized to minimize drive time. Skill requirements are respected. SLAs appear covered. A small amount of capacity is reserved for reactive maintenance “just in case”.
On screen, the ppm maintenance schedule looks coherent. Balanced. Defensible.
This plan assumes three things:
-
Jobs will take roughly as long as expected
-
Technicians will start on time and move as planned
-
Reactive demand will fit into the gaps provided
All three assumptions are fragile.
The plan looks reasonable. It almost never survives intact past mid-morning.
First Reactive Job: The Plan Starts to Bend
A critical reactive job arrives. It can't wait. The SLA overrides the plan.
The planner needs to decide quickly who to divert. But real-time visibility is partial at best. Technician progress is delayed or inferred. Field data arrives through phone calls, texts, or delayed system updates. Decisions are made with incomplete information.
A technician is reassigned. One preventive visit is pushed back. The route is broken. The ppm scheduling logic no longer holds.
This isn't chaos, yet. This is just the first compromise.
Second Overrun: Compounding Begins
Shortly after, another job runs longer than expected. Not dramatically. Twenty minutes. Maybe thirty.
That technician now misses their next customer window. The planner intervenes again. Another adjustment is made. Another preventive visit is moved or shortened.
This is where linear thinking fails.
Reactive maintenance doesn't replace preventive work cleanly. It collides with it. Each reactive insertion distorts multiple downstream assumptions: travel time, start times, workload balance, and technician availability.
Small overruns combine. Their effects multiply.
Planner Intervention: Firefighting Mode
By late morning, the planner is no longer managing a schedule. They are reacting to events.
Schedules are adjusted repeatedly. Each change requires validation: skills, compliance, customer availability, travel time, and knock-on effects. Administrative load spikes. Cognitive load becomes constant.
With every manual intervention, risk increases. Double bookings appear. Appointments are missed. Jobs are assigned to technicians with marginal skill fit. Start times drift. Errors creep in.
This isn't due to negligence. It is due to volume.
The number of micro-decisions exceeds what a human can safely process in real time. Burnout begins early in the day. Decision quality declines. The system becomes brittle.
Inventory and Asset Issues Surface Too Late
As pressure mounts, inventory and asset constraints surface—often only when the technician is already on site.
A required part is missing. The wrong equipment was loaded. A vehicle was double-booked. These failures were invisible during planning because planning and execution are disconnected.
Jobs fail on site. Repeat visits are required. Preventive work is deferred again. Reactive demand increases further.
What was meant to stabilize operations now generates more disruption.
Knock-On Effects Across the Operation
By mid-afternoon, the effects are visible everywhere.
Response times slip. Appointments are missed or rushed. Some technicians accumulate overtime while others wait idle due to misalignment. Compliance checks are deferred. SLA risk increases quietly until it becomes explicit.
The organization appears busy but inefficient. Activity increases. Control decreases.
Loss of Route Integrity
Optimized routes no longer matter. Skill-based routing degrades under pressure. Technicians begin making local decisions to cope.
They choose routes that feel safer. They avoid risky jobs. They cluster work informally. This is rational behavior in an unstable system.
But it further increases drive time and erodes whatever optimization remains.
Rising Drive Time, Idle Time, and Cost
High drive time combines with idle time and overtime. Operating costs rise sharply. Cost-to-serve becomes unpredictable. Margins erode without a clear root cause.
From the outside, it looks like poor execution. Internally, it feels like constant effort with diminishing returns.
End of Day: Tomorrow Is Already Broken
The planner ends the day exhausted. The schedule for tomorrow has already absorbed today’s compromises. Preventive work has been deferred. Reactive demand remains high.
The ppm schedules for the next day are built on unstable ground.
This loop repeats daily.
Not because teams are failing—but because static scheduling can't survive continuous change at scale.
Why Adding Planners or “Better Processes” Fails
When control slips, organizations respond logically. They hire more planners. They introduce more process. They hold more meetings.
This feels rational. It is also ineffective.
The False Reality
More planners appear to spread the load. More process appears to reduce mistakes. In reality, coordination overhead increases. Decisions slow down. Conflicts multiply.
Human trade-offs replace mathematical optimization. Each planner optimizes locally. No one sees the system as a whole.
The Actual Outcomes
Diminishing returns set in quickly. Costs rise. Control doesn't return. The operation becomes more complex, not less.
You can't scale human judgment to solve a problem that is fundamentally combinatorial.
Why FSM Tools and Static Scheduling Can’t Solve This
Field Service Management (FSM) tools are essential to modern field operations. This includes Computer-Aided Facility Management (CAFM), Enterprise Resource Planning (ERP), and Customer Relationship Management (CRM) Software.
These tools act as systems of record. They store jobs, assets, service history, warranties, compliance evidence, and customer data. CMMS functionality within these platforms provides proof of maintenance, which lowers insurance premiums and reduces liability exposure.
None of that is the problem.
The limitation appears when FSM tools are expected to run daily operations under constant change.
Most FSM scheduling modules are built around periodic optimization. They assume a schedule can be created, dispatched, and largely followed. When disruption occurs, the system is re-optimized in batches—hourly, daily, or manually.
This model assumes relative stability.
That assumption no longer holds once operations pass meaningful scale. Even in organizations where 80% of work is planned in advance, the remaining 20% is urgent, reactive demand.
At scale, this isn't chaos. It's organized, continuous interruption. Reactive maintenance doesn't arrive as a single event. It arrives as a stream.
Batch optimization breaks down in this environment. Each re-optimization is based on assumptions that are already outdated: technician progress, job duration, travel time, parts availability. By the time a new schedule is produced, the field has already diverged from it.
The result is predictable. Schedules drift. Manual overrides increase. Dispatchers step in to “fix” the plan. Scheduling 50+ people often requires multiple full-time dispatchers simply to keep the day moving.
Managers feel this pressure directly. In many organizations, managers spend between three and ten hours per week just creating or adjusting schedules. That time is taken away from strategic work: improving service models, reducing cost-to-serve, or modernizing maintenance strategies.
Meanwhile, technician utilization suffers. Technicians spend too much time traveling between jobs, often because routes are broken repeatedly throughout the day. Industry data shows average technician utilization is around 73%, with excess drive time being one of the primary causes.
FSM tools can report this after the fact. They struggle to prevent it in real time.
The deeper issue is structural. Static scheduling assumes the world pauses between updates. Field operations don't.
PPM and reactive maintenance require continuous decision-making, not periodic planning.
What Scalable Operations Do Differently
Scalable operations accept a hard truth early: planning alone doesn't create control.
They still plan. Planned preventive maintenance schedules remain critical. Scaling PPM consistently delivers results according to data:
Total maintenance costs drop by 5–20% compared to purely reactive strategies. Assets that are regularly maintained last 30–40% longer, delaying capital expenditure and stabilizing long-term budgets.
By contrast, reactive fixes cost three to five times more than planned maintenance due to overtime labor, rush shipping, and secondary damage. The economics of PPM isn't the question.
What changes at scale is how plans are executed.
Scalable organizations treat plans as starting points, not commitments. They assume disruption will happen and design for it. Continuous re-optimization replaces fixed schedules. Decisions are evaluated dynamically as conditions change, not retrospectively once damage is done.
Rules replace manual judgment wherever possible. Priority logic, SLA enforcement, skills, compliance, and working-time rules are applied consistently by the system, not reinterpreted by humans under pressure. This reduces error and cognitive load without removing accountability.
Planners and dispatchers shift roles. They stop micromanaging individual job moves. Instead, they supervise outcomes: utilization, SLA compliance, overtime exposure, and risk. Exceptions become visible earlier, when there are still multiple good options available.
Capacity is managed in real time. Travel time is treated as a first-class constraint, not an unavoidable side effect. This directly addresses the utilization gap caused by excessive driving.
Crucially, scalable operations don't pretend the 80/20 ideal is already reality.
Many large organizations actually spend 34–45% of their time on reactive maintenance due to aging assets, regulatory pressure, or incomplete digitalization. Execution systems are designed to operate effectively in that reality, not an aspirational one.
Over time, execution data becomes the lever for improvement. Field data feeds analytics. Maintenance strategies gradually shift from purely time-based PPM toward usage-based and predictive models. When done correctly, this can cut unplanned downtime by up to 50%.
But that transition is impossible without first mastering execution.
Scalable operations understand this sequence. They don't try to optimize tomorrow’s strategy while losing control of today’s reality. They build execution capability first, and then use the resulting data to evolve.
Execution becomes a live system, not a static document.
How Can eLogii Help You to Scale PPM Scheduling + Reactive Jobs Beyond 50 Technicians
eLogii operates as the execution layer between planning intent and field reality.

Most field organizations already have planning systems:
-
FSM platforms define jobs, assets, SLAs, customers, and technicians.
-
ERP systems manage costs and inventory.
-
CRM systems manage relationships.
These systems are essential. They are systems of record.
What they aren't designed to do is continuously manage change.
eLogii exists in the gap that appears once planned preventive maintenance schedules meet real-world volatility. It doesn't replace upstream planning. It assumes that a plan exists. Its role begins the moment that plan encounters disruption.
At scale, ppm scheduling isn't a one-time optimization problem. It's a continuous decision problem. Conditions change minute by minute: reactive maintenance arrives, jobs overrun, traffic shifts, technicians become unavailable, parts run short, SLAs tighten.
eLogii is designed specifically for this environment.
Instead of treating schedules as static commitments, it treats ppm schedules as evolving structures. The original ppm maintenance schedule becomes a baseline, not a constraint. As conditions change, trade-offs are evaluated continuously rather than periodically.
This matters because field operations aren't failing due to lack of planning effort. They fail because decisions are made too late, with partial information, and under extreme cognitive load.
eLogii enforces operational rules consistently and at scale. Priority logic, SLA obligations, skills, compliance constraints, working time rules, and route efficiency are applied mathematically, not manually. This removes the need for planners to constantly re-evaluate the same trade-offs under pressure.
Crucially, this doesn't eliminate human oversight. It changes it.
Planners stop micromanaging individual job moves. Instead, they supervise outcomes: service levels, utilization, risk exposure, and cost. Exceptions become visible earlier. Decisions become explainable. Control is restored without adding headcount.
Route integrity is preserved for as long as possible, even as disruption occurs. Preventive and reactive maintenance are balanced dynamically rather than competing destructively. Drive time, idle time, and overtime are managed as system-level outcomes, not after-the-fact reports.
Because eLogii sits alongside FSM, CRM, ERP, and telematics systems, organizations don't need to rip and replace their existing stack. Planning intent remains upstream. Execution intelligence lives downstream.
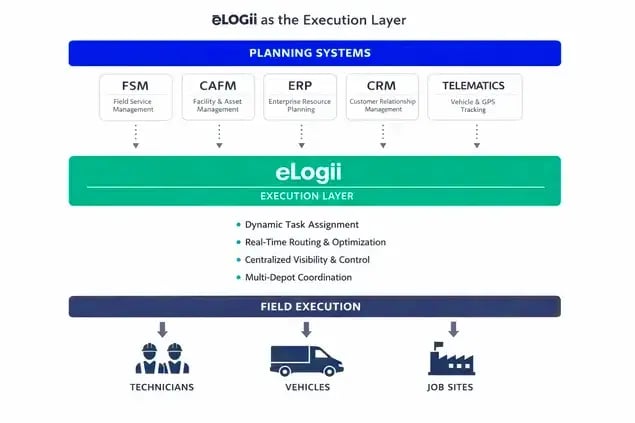
The distinction is subtle but critical.
Static scheduling assumes the world will mostly cooperate. Execution layers assume it won't!
When ppm and reactive maintenance dominate daily operations, execution is where control is either lost, or regained.
Service Execution Management: Who Is This Approach For (and Isn't)
Not every field operation faces the same level of complexity.
This model is designed for organizations where scale, variability, and service pressure are already limiting performance.
This table will let you know when an execution-layer approach makes sense, and when simpler planning methods are still sufficient.
| |
This Model Is Right For
|
This Model Isn't Right For
|
|
Team Size
|
50+ field technicians or engineers where manual scheduling and dispatcher oversight no longer scale
|
Small teams where one planner can manage schedules end-to-end without constant rework
|
|
Geography
|
Multi-region or multi-depot operations with long travel distances and overlapping service territories
|
Single-location or compact geographies with predictable travel and minimal routing complexity
|
|
Work Mix
|
Mixed PPM and reactive maintenance with continuous same-day disruption and frequent reprioritization
|
Purely preventive maintenance with fixed routes and low interruption rates
|
|
Service Pressure
|
SLA-driven service environments where response times, compliance, and penalties materially affect performance
|
Price-driven service models where delays or missed appointments have limited consequences
|
|
Skill Complexity
|
Complex skills, certifications, and compliance constraints that tightly limit who can do what and when
|
Simple, repeatable tasks that any technician can perform interchangeably
|
|
Utilization Risk
|
High utilization pressure where travel time, idle time, and overtime directly impact margins
|
Low utilization pressure where excess capacity absorbs inefficiencies
|
|
Operational Goal
|
Operations seeking control at scale, not just better-looking schedules
|
Operations seeking basic scheduling, not continuous execution optimization
|
Bottom Line: PPM Scheduling Isn't Broken, It's Incomplete Without Execution
PPM scheduling fails at scale because it's incomplete. Not because it's wrong.
Preventive and reactive maintenance create continuous change. Static plans can't handle it. Manual intervention can't scale indefinitely.
Beyond 50 technicians, control comes from execution, not better calendars.
If your operation feels permanently one disruption away from chaos, the problem is structural.
The solution isn't more effort. It's a different layer of control.
The next step Isn't replacing your systems. It's recognizing where planning ends and execution must begin.
And we can help you make that first step RIGHT NOW.





